- Медицинский ИИ: Как мы научили машины понимать истории болезни
- Почему это важно?
- Наш подход к разработке
- Сбор и предобработка данных: первый шаг к успеху
- Извлечение ключевой информации: NLP в действии
- Суммирование информации: создание краткого и понятного резюме
- Технологии, которые мы использовали
- Вызовы и решения
- Результаты и перспективы
Медицинский ИИ: Как мы научили машины понимать истории болезни
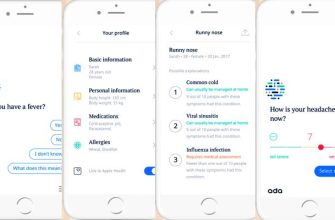
Привет, друзья! Сегодня мы хотим поделиться с вами захватывающим опытом разработки системы анализа медицинских текстов, а именно – автоматического суммирования выписок из историй болезни․ Это был долгий и тернистый путь, полный интересных открытий и неожиданных вызовов․ Надеемся, что наш опыт будет полезен тем, кто интересуется искусственным интеллектом в медицине․
Представьте себе: горы медицинских документов, написанных сложным языком, с множеством сокращений и терминов․ Врачам приходится тратить огромное количество времени на изучение этих документов, чтобы получить полное представление о состоянии пациента․ Наша цель – создать инструмент, который сможет автоматически извлекать ключевую информацию из этих текстов и представлять ее в виде краткого и понятного резюме․
Почему это важно?
Автоматическое суммирование медицинских текстов – это не просто модный тренд, а насущная необходимость․ Вот лишь несколько причин, почему это важно:
- Экономия времени врачей: Врачи смогут тратить меньше времени на чтение документов и больше – на общение с пациентами․
- Улучшение качества медицинской помощи: Более быстрый и точный анализ информации позволит врачам принимать более обоснованные решения․
- Снижение риска ошибок: Автоматизация исключает человеческий фактор, что снижает вероятность ошибок при анализе данных․
- Оптимизация работы медицинских учреждений: Автоматизация процессов позволит медицинским учреждениям работать более эффективно․
Мы верим, что подобные системы могут значительно улучшить качество медицинской помощи и сделать ее более доступной для всех․
Наш подход к разработке
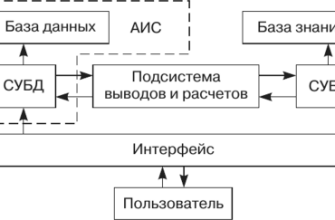
Разработка системы анализа медицинских текстов – это сложная задача, требующая комплексного подхода․ Мы разбили эту задачу на несколько этапов:
- Сбор и предобработка данных: Мы собрали большую коллекцию медицинских текстов, включая выписки из историй болезни, результаты анализов и консультации врачей․ Затем мы провели предобработку данных, удалив лишние символы, исправив опечатки и приведя текст к единому формату․
- Извлечение ключевой информации: На этом этапе мы использовали методы обработки естественного языка (NLP) для извлечения ключевой информации из текстов, такой как диагнозы, симптомы, назначения лекарств и результаты анализов․
- Суммирование информации: Мы разработали алгоритм, который автоматически суммирует извлеченную информацию и представляет ее в виде краткого и понятного резюме․
- Оценка качества: Мы провели оценку качества нашей системы, сравнив ее результаты с результатами, полученными врачами;
Каждый из этих этапов представлял собой отдельную задачу, требующую глубокого понимания как медицинских, так и технических аспектов․
Сбор и предобработка данных: первый шаг к успеху
Этот этап был одним из самых трудоемких․ Мы столкнулись с множеством проблем, связанных с неоднородностью данных, использованием медицинского жаргона и сокращений, а также с различиями в форматах документов․ Нам пришлось разработать специальные методы для обработки этих данных, включая:
- Автоматическое распознавание текста (OCR): Для обработки отсканированных документов․
- Нормализацию текста: Для приведения текста к единому формату․
- Разрешение сокращений и аббревиатур: С использованием медицинских словарей и баз знаний․
Только после тщательной предобработки данных мы смогли перейти к следующему этапу – извлечению ключевой информации․
Извлечение ключевой информации: NLP в действии
На этом этапе мы использовали различные методы NLP, включая:
- Именованное распознавание сущностей (NER): Для выделения медицинских терминов, таких как диагнозы, симптомы и лекарства․
- Отношения между сущностями: Для определения связей между различными сущностями, например, между симптомом и диагнозом․
- Анализ тональности: Для определения эмоциональной окраски текста, например, для выявления негативных отзывов пациентов․
Мы использовали как готовые NLP-библиотеки, так и разрабатывали собственные алгоритмы, адаптированные к специфике медицинских текстов․ Этот этап был критически важным для получения точной и полезной информации․
Суммирование информации: создание краткого и понятного резюме
На этом этапе мы столкнулись с задачей представления извлеченной информации в виде краткого и понятного резюме․ Мы использовали различные методы суммирования, включая:
- Экстрактивное суммирование: Выбор наиболее важных предложений из исходного текста․
- Абстрактивное суммирование: Генерация нового текста, содержащего ключевую информацию․
Мы также учитывали важность различных типов информации, например, диагнозы и назначения лекарств имели больший вес, чем общие замечания врача․ В результате мы получили систему, которая может генерировать краткие и информативные резюме медицинских текстов․
«Искусственный интеллект не заменит врачей, но врачи, использующие искусственный интеллект, заменят тех, кто его не использует․» ⏤ Д-р Эрик Тополь
Технологии, которые мы использовали
В процессе разработки мы использовали широкий спектр технологий, включая:
- Python: Основной язык программирования․
- TensorFlow и PyTorch: Для разработки и обучения моделей машинного обучения․
- spaCy и NLTK: Для обработки естественного языка․
- Docker и Kubernetes: Для развертывания и масштабирования системы․
Выбор технологий зависел от конкретной задачи и доступности ресурсов․ Мы старались использовать самые современные и эффективные инструменты․
Вызовы и решения
Разработка системы анализа медицинских текстов – это нелегкая задача, и мы столкнулись с рядом вызовов:
- Нехватка данных: Доступ к медицинским данным ограничен, и нам пришлось приложить немало усилий, чтобы собрать достаточное количество данных для обучения моделей․
- Сложность языка: Медицинский язык сложен и требует глубокого понимания терминологии и контекста․
- Оценка качества: Оценка качества автоматического суммирования – это сложная задача, требующая привлечения экспертов․
Мы преодолели эти вызовы благодаря упорству, креативности и сотрудничеству с медицинскими экспертами․
Результаты и перспективы
Наша система показала хорошие результаты в автоматическом суммировании выписок из историй болезни․ Она позволяет врачам быстро получать ключевую информацию о состоянии пациента и принимать более обоснованные решения․ Мы продолжаем работать над улучшением нашей системы и планируем расширить ее функциональность, добавив возможность анализа других типов медицинских текстов, таких как результаты анализов и консультации врачей․
Мы уверены, что искусственный интеллект может сыграть важную роль в медицине и помочь врачам оказывать более качественную помощь пациентам․ Наша работа – это лишь небольшой шаг в этом направлении, но мы надеемся, что она вдохновит других разработчиков на создание новых и полезных инструментов для медицины․
Разработка систем анализа медицинских текстов – это сложная, но очень важная задача․ Мы надеемся, что наш опыт будет полезен тем, кто интересуется этой областью․ Мы верим, что искусственный интеллект может значительно улучшить качество медицинской помощи и сделать ее более доступной для всех․
Подробнее
| Анализ медицинских документов ИИ | Автоматическое суммирование истории болезни | Обработка естественного языка в медицине | Медицинский NLP | Извлечение информации из медицинских текстов |
|---|---|---|---|---|
| Искусственный интеллект в здравоохранении | Суммирование медицинских выписок | Автоматизация анализа историй болезни | Медицинский текстовый анализ | ИИ для врачей |