- Медицинский ИИ: Как Классификация Текстов Спасает Жизни
- Почему Классификация Медицинских Текстов Так Важна?
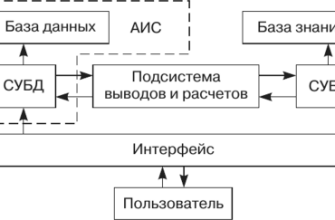
- Как Работает Система Классификации Медицинских Текстов?
- Основные Алгоритмы Классификации
- Практические Применения Классификации Медицинских Текстов
- Проблемы и Вызовы
- Будущее Классификации Медицинских Текстов
Медицинский ИИ: Как Классификация Текстов Спасает Жизни
В современном мире, где объемы медицинской информации растут экспоненциально, задача автоматизированной обработки и анализа этих данных становится критически важной․ Мы, как разработчики и исследователи, сталкиваемся с необходимостью создавать системы, способные извлекать ценные знания из огромного количества текстовых записей․ Эти записи включают в себя все: от историй болезни и результатов анализов до научных статей и клинических рекомендаций․ Без эффективных инструментов анализа эта информация остается неиспользованным потенциалом, который мог бы значительно улучшить качество медицинской помощи․
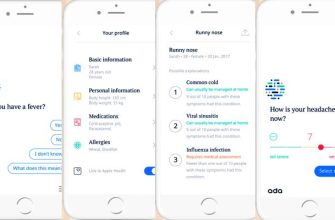
Представьте себе врача, которому нужно быстро принять решение о лечении пациента, имея под рукой лишь разрозненные текстовые данные․ Времени на подробное изучение всех документов просто нет; Здесь на помощь приходят системы классификации медицинских текстов, которые могут автоматически определить тематику, срочность или другие важные характеристики текста․ Это позволяет врачу сосредоточиться на наиболее релевантной информации и принять обоснованное решение в кратчайшие сроки․
Почему Классификация Медицинских Текстов Так Важна?
Классификация медицинских текстов – это не просто модный тренд в IT, это жизненно необходимая технология, которая может изменить подход к здравоохранению; Она позволяет:
- Ускорить диагностику: Автоматически классифицировать симптомы и результаты анализов, чтобы помочь врачу быстрее поставить диагноз․
- Улучшить лечение: Находить наиболее эффективные методы лечения на основе анализа историй болезни и научных публикаций․
- Снизить количество ошибок: Выявлять потенциальные ошибки в назначениях лекарств или протоколах лечения․
- Оптимизировать работу медицинского персонала: Автоматизировать рутинные задачи, такие как сортировка документов и поиск информации․
- Проводить научные исследования: Анализировать большие объемы данных для выявления новых закономерностей и факторов риска заболеваний․
Мы видим, как эти возможности постепенно становятся реальностью, и это вдохновляет нас на дальнейшие исследования и разработки․
Как Работает Система Классификации Медицинских Текстов?
В основе любой системы классификации лежит алгоритм машинного обучения․ Мы обучаем этот алгоритм на большом количестве размеченных данных – то есть на текстах, для которых уже известна правильная классификация․ Например, мы можем обучить систему различать тексты, описывающие различные типы заболеваний, или определять срочность обращения пациента в больницу․
Процесс обучения включает в себя несколько этапов:
- Сбор данных: Мы собираем как можно больше медицинских текстов различных типов․
- Предварительная обработка: Мы очищаем тексты от лишней информации, такой как знаки препинания и стоп-слова, и приводим их к единому формату․
- Извлечение признаков: Мы определяем, какие слова и фразы наиболее важны для классификации․ Например, для определения типа заболевания важны названия симптомов и лекарств․
- Обучение модели: Мы используем алгоритм машинного обучения для построения модели, которая может предсказывать класс текста на основе извлеченных признаков․
- Оценка качества: Мы проверяем, насколько хорошо модель работает на новых, ранее не виденных данных․
Этот процесс требует значительных усилий и экспертизы, но результат того стоит – мы получаем систему, способную с высокой точностью классифицировать медицинские тексты․
Основные Алгоритмы Классификации
Существует множество алгоритмов машинного обучения, которые можно использовать для классификации текстов․ Мы часто используем следующие:
- Наивный байесовский классификатор: Простой и быстрый алгоритм, который хорошо подходит для задач с большим количеством признаков․
- Метод опорных векторов (SVM): Более сложный алгоритм, который обеспечивает высокую точность классификации, особенно в задачах с небольшим объемом данных․
- Логистическая регрессия: Линейная модель, которая хорошо подходит для задач бинарной классификации․
- Нейронные сети: Самые современные алгоритмы, которые могут достигать очень высокой точности, но требуют большого количества данных и вычислительных ресурсов․ Особенно популярны рекуррентные нейронные сети (RNN) и трансформеры․
Выбор конкретного алгоритма зависит от задачи и доступных данных․ Мы всегда проводим эксперименты с разными алгоритмами, чтобы выбрать наиболее подходящий․
«Цель науки – предвидеть․ »
– Огюст Конт
Практические Применения Классификации Медицинских Текстов
Область применения систем классификации медицинских текстов практически безгранична․ Вот лишь несколько примеров:
- Автоматическая сортировка входящей корреспонденции в больнице: Система может автоматически определять тип документа (например, письмо от страховой компании, результат анализа, жалоба пациента) и направлять его нужному специалисту․
- Выявление пациентов с высоким риском развития определенного заболевания: Система может анализировать истории болезни и выявлять пациентов, у которых есть факторы риска развития, например, диабета или сердечно-сосудистых заболеваний․
- Поиск информации в медицинских базах данных: Система может помочь врачу быстро найти нужную информацию, например, о побочных эффектах лекарства или о новых методах лечения․
- Анализ отзывов пациентов: Система может анализировать отзывы пациентов о работе больницы и выявлять проблемные места․
Мы верим, что в будущем системы классификации медицинских текстов станут незаменимым инструментом для врачей и других медицинских работников․
Проблемы и Вызовы
Несмотря на все преимущества, разработка систем классификации медицинских текстов сопряжена с рядом проблем и вызовов:
- Недостаток размеченных данных: Для обучения алгоритмов машинного обучения требуется большое количество размеченных данных, которых часто не хватает в медицинской сфере․
- Конфиденциальность данных: Медицинские данные являются конфиденциальными, и их использование ограничено законодательством․
- Сложность медицинской терминологии: Медицинские тексты часто содержат сложную терминологию, которую трудно понять алгоритмам машинного обучения․
- Неоднозначность текстов: Медицинские тексты часто содержат неоднозначные формулировки, которые могут быть интерпретированы по-разному․
Мы постоянно работаем над решением этих проблем, разрабатывая новые методы обучения на небольшом количестве данных, используя методы анонимизации данных и разрабатывая алгоритмы, способные понимать сложную медицинскую терминологию․
Будущее Классификации Медицинских Текстов
Мы видим будущее классификации медицинских текстов в тесной интеграции с другими технологиями, такими как искусственный интеллект, большие данные и облачные вычисления․ Мы верим, что в будущем системы классификации медицинских текстов будут способны:
- Автоматически извлекать знания из медицинских текстов и представлять их в удобной для пользователя форме․
- Помогать врачам принимать более обоснованные решения на основе анализа больших объемов данных․
- Персонализировать лечение пациентов на основе их индивидуальных характеристик․
- Предотвращать развитие заболеваний на основе анализа факторов риска․
Мы стремимся к тому, чтобы эти возможности стали реальностью, и работаем над созданием новых, более эффективных и безопасных систем классификации медицинских текстов․
Подробнее
| LSI Запрос | LSI Запрос | LSI Запрос | LSI Запрос | LSI Запрос |
|---|---|---|---|---|
| Анализ медицинских документов | Классификация историй болезни | Машинное обучение в медицине | Обработка естественного языка в здравоохранении | ИИ в медицинской диагностике |
| Системы поддержки принятия решений в медицине | Автоматическая интерпретация медицинских текстов | Анализ медицинских отчетов | Методы классификации текстов | Применение NLP в медицине |