- Преобразуя крик души в диагноз: наш опыт разработки системы анализа медицинских текстов
- Первые шаги: сбор и подготовка данных
- Предварительная обработка текста: наши методы
- Выбор модели машинного обучения
- Архитектура нашей системы
- Обучение и оценка модели
- Проблемы и решения
- Преодоление трудностей: наш опыт
- Результаты и перспективы
- Дальнейшее развитие системы
Преобразуя крик души в диагноз: наш опыт разработки системы анализа медицинских текстов
В мире‚ где каждый день медицинские работники сталкиваются с огромным потоком информации‚ автоматизация анализа медицинских текстов становится не просто желательной‚ а необходимой. Мы‚ как команда разработчиков‚ решили принять этот вызов и поделиться нашим опытом создания системы‚ способной классифицировать жалобы пациентов‚ облегчая работу врачей и повышая качество медицинской помощи.
Наш путь начался с осознания проблемы: врачи тратят драгоценное время на ручной анализ текстовых записей‚ жалоб и историй болезней. Это не только замедляет процесс диагностики‚ но и увеличивает вероятность ошибок. Мы поставили перед собой цель – разработать систему‚ которая сможет автоматически извлекать ключевую информацию из текста‚ классифицировать жалобы по категориям и предоставлять врачам структурированные данные для принятия решений.
Первые шаги: сбор и подготовка данных
Любая система машинного обучения начинается с данных. В нашем случае‚ это были медицинские тексты – жалобы пациентов‚ истории болезней‚ результаты обследований. Сбор данных оказался непростой задачей‚ поскольку медицинская информация часто является конфиденциальной и требует соблюдения строгих правил и норм. Мы работали с медицинскими учреждениями‚ чтобы получить доступ к анонимизированным данным‚ соблюдая все требования безопасности и конфиденциальности.
После сбора данных началась их подготовка. Медицинские тексты часто содержат опечатки‚ сокращения‚ медицинский жаргон и другую специфическую лексику. Мы разработали специальные алгоритмы для очистки и нормализации текста‚ чтобы привести его к единообразному формату‚ пригодному для анализа. Этот этап включал в себя удаление лишних символов‚ исправление опечаток‚ расшифровку сокращений и замену медицинских терминов на стандартные.
Предварительная обработка текста: наши методы
Для предварительной обработки текста мы использовали несколько методов:
- Токенизация: Разбиение текста на отдельные слова или токены.
- Удаление стоп-слов: Исключение из текста часто встречающихся слов‚ не несущих смысловой нагрузки (например‚ «и»‚ «в»‚ «на»).
- Лемматизация: Приведение слов к их начальной форме (например‚ «бежал» -> «бежать»).
- Стемминг: Усечение слов до их основы (например‚ «бегающий» -> «бега»).
Каждый из этих методов играет важную роль в подготовке текста к анализу. Токенизация позволяет разбить текст на отдельные элементы‚ которые затем можно анализировать. Удаление стоп-слов помогает избавиться от лишней информации‚ которая может затруднить анализ. Лемматизация и стемминг приводят слова к их базовой форме‚ что позволяет учитывать различные формы одного и того же слова.
Выбор модели машинного обучения
После подготовки данных мы приступили к выбору модели машинного обучения. Мы рассматривали различные варианты‚ включая наивный байесовский классификатор‚ метод опорных векторов (SVM) и глубокое обучение с использованием нейронных сетей. В конечном итоге‚ мы остановились на использовании трансформеров‚ таких как BERT (Bidirectional Encoder Representations from Transformers)‚ которые показали отличные результаты в задачах обработки естественного языка.
Трансформеры отличаются от традиционных моделей машинного обучения тем‚ что они учитывают контекст слова в предложении‚ что позволяет им более точно понимать смысл текста. BERT‚ в частности‚ был обучен на огромном объеме текстовых данных и способен генерировать контекстуализированные представления слов‚ что делает его идеальным для задач классификации текста.
Архитектура нашей системы
Наша система состоит из нескольких основных компонентов:
- Модуль предварительной обработки текста: Очищает и нормализует текст‚ подготавливая его к анализу.
- Модуль извлечения признаков: Преобразует текст в числовые векторы‚ пригодные для машинного обучения.
- Модуль классификации: Классифицирует жалобы по категориям с использованием модели BERT.
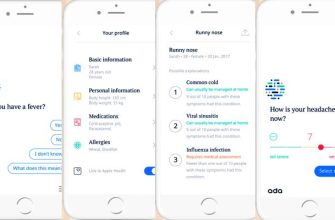
- Модуль визуализации: Представляет результаты анализа в удобном для врачей формате.
Каждый из этих модулей играет важную роль в работе системы. Модуль предварительной обработки текста обеспечивает качество входных данных. Модуль извлечения признаков преобразует текст в формат‚ понятный для модели машинного обучения. Модуль классификации определяет категорию жалобы. Модуль визуализации предоставляет врачам структурированную информацию для принятия решений.
Обучение и оценка модели
Обучение модели BERT – это ресурсоемкий процесс‚ требующий большого объема вычислительных мощностей. Мы использовали облачные сервисы для обучения модели на большом объеме данных. В процессе обучения мы использовали различные методы регуляризации‚ чтобы предотвратить переобучение модели и повысить ее обобщающую способность.
После обучения модели мы провели ее оценку на тестовом наборе данных. Мы использовали различные метрики‚ такие как точность‚ полнота и F1-мера‚ чтобы оценить качество классификации. Результаты показали‚ что наша система достигла высокой точности классификации‚ превосходя другие модели машинного обучения.
«Цель науки ⏤ упрощать сложное‚ а не усложнять простое;» ⏤ Альберт Эйнштейн
Проблемы и решения
В процессе разработки системы мы столкнулись с рядом проблем. Одной из главных проблем была нехватка размеченных данных. Для обучения модели BERT требуется большой объем размеченных данных‚ а получить такие данные в медицинской сфере – непростая задача. Мы решили эту проблему‚ используя методы полуавтоматической разметки данных‚ которые позволили нам значительно увеличить объем размеченных данных.
Другой проблемой была обработка медицинского жаргона и сокращений. Медицинские тексты часто содержат специфическую лексику‚ которая может быть непонятна для модели машинного обучения. Мы разработали специальный словарь медицинских терминов и сокращений‚ который позволил нам расшифровывать медицинский жаргон и приводить текст к стандартному формату.
Преодоление трудностей: наш опыт
Вот некоторые из трудностей‚ с которыми мы столкнулись‚ и наши решения:
- Нехватка данных: Использование методов полуавтоматической разметки данных.
- Медицинский жаргон: Разработка словаря медицинских терминов и сокращений.
- Опечатки и ошибки: Использование алгоритмов исправления опечаток.
- Неструктурированный текст: Разработка правил для извлечения информации из неструктурированного текста.
Результаты и перспективы
В результате нашей работы мы создали систему‚ которая способна автоматически классифицировать жалобы пациентов с высокой точностью. Эта система может помочь врачам быстрее и эффективнее анализировать медицинские тексты‚ что приведет к улучшению качества медицинской помощи. Мы планируем продолжить развитие нашей системы‚ добавляя новые функции и расширяя ее возможности.
В будущем мы хотим интегрировать нашу систему с другими медицинскими информационными системами‚ чтобы обеспечить бесшовный обмен данными между различными системами. Мы также планируем разработать мобильное приложение‚ которое позволит врачам получать доступ к результатам анализа в любое время и в любом месте.
Дальнейшее развитие системы
Наши планы на будущее:
- Интеграция с медицинскими информационными системами.
- Разработка мобильного приложения.
- Добавление новых функций‚ таких как автоматическое формирование диагноза.
- Расширение на другие языки.
Разработка системы анализа медицинских текстов – это сложная‚ но важная задача. Мы надеемся‚ что наш опыт будет полезен другим разработчикам‚ работающим в этой области. Мы верим‚ что автоматизация анализа медицинских текстов может значительно улучшить качество медицинской помощи и облегчить работу врачей.
Мы гордимся тем‚ что внесли свой вклад в развитие медицинских технологий. Мы надеемся‚ что наша система поможет врачам спасать жизни и улучшать здоровье людей. Мы будем продолжать работать над улучшением нашей системы‚ чтобы она стала еще более полезной и эффективной.
Подробнее
| Анализ медицинских текстов | Классификация жалоб пациентов | Машинное обучение в медицине | Обработка естественного языка | Автоматизация медицинской диагностики |
|---|---|---|---|---|
| BERT для медицинских текстов | Извлечение информации из медицинских записей | Системы поддержки принятия решений в медицине | Анализ текстовых данных в здравоохранении | Применение ИИ в медицине |