Медицинский Шерлок Холмс: Как мы научили компьютер понимать язык врачей
В современном мире, где объемы медицинской информации растут в геометрической прогрессии, задача извлечения полезных данных из медицинских текстов становится все более актуальной. Представьте себе, сколько времени врачи тратят на прочтение историй болезни, научных статей и результатов исследований. И что, если бы существовал инструмент, способный быстро и точно анализировать эту информацию, выделяя ключевые факты и сущности? Мы решили создать такого помощника – «медицинского Шерлока Холмса», который бы помогал врачам и исследователям в их нелегком труде.
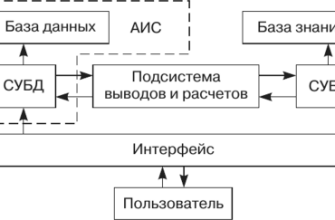
Наш путь к созданию системы анализа медицинских текстов был полон вызовов и открытий. Мы столкнулись с необходимостью обработки неструктурированных данных, распознавания медицинской терминологии и учета контекста, в котором используются те или иные термины. Но, шаг за шагом, мы приближались к цели – созданию интеллектуального инструмента, способного понимать язык врачей.
Что такое извлечение сущностей и зачем оно нужно в медицине?
Извлечение сущностей (Named Entity Recognition, NER) – это процесс идентификации и классификации именованных сущностей в тексте. В контексте медицины, это могут быть названия болезней, лекарственных препаратов, симптомов, анатомических областей, результатов анализов и т.д. Представьте себе, что у вас есть огромный текст с описанием клинического случая. Система NER поможет автоматически выделить из этого текста все ключевые медицинские понятия.
Зачем это нужно? Вариантов применения масса:
- Улучшение качества медицинской документации: Автоматическое заполнение полей в электронных медицинских картах, сокращение времени на ввод данных.
- Поддержка принятия клинических решений: Быстрый поиск информации о пациенте, выявление закономерностей и рисков.
- Фармацевтические исследования: Анализ данных о побочных эффектах лекарственных препаратов, выявление новых показаний.
- Поиск медицинской информации: Улучшение релевантности результатов поиска в медицинских базах данных и библиотеках.
Наши подходы к разработке системы
Мы использовали комбинацию различных подходов, чтобы добиться максимальной точности и эффективности нашей системы:
- Правила, основанные на словарях и шаблонах: Мы создали обширные словари медицинских терминов и шаблоны, описывающие типичные конструкции предложений. Этот подход позволяет быстро и точно извлекать сущности, но требует постоянного обновления словарей и шаблонов.
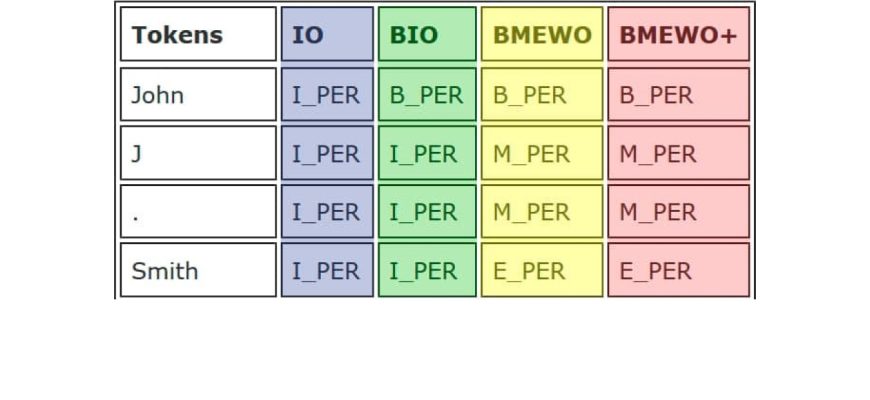
- Методы машинного обучения: Мы обучили модели машинного обучения на большом объеме размеченных медицинских текстов. Эти модели способны распознавать сущности, даже если они не встречаются в наших словарях. Мы использовали такие алгоритмы, как Conditional Random Fields (CRF) и Recurrent Neural Networks (RNN).
- Гибридный подход: Мы объединили преимущества обоих подходов, чтобы создать систему, которая одновременно является точной и гибкой. Правила используются для извлечения наиболее распространенных сущностей, а машинное обучение – для обработки более сложных случаев.
Сбор и разметка данных
Одним из самых трудоемких этапов разработки была сбор и разметка данных. Нам потребовалось собрать огромный объем медицинских текстов из различных источников: истории болезни, научные статьи, клинические руководства и т.д. Затем, мы вручную разметили эти тексты, указав, какие слова и фразы являются медицинскими сущностями и к какому типу они относятся. Это была кропотливая работа, но она была необходима для обучения наших моделей машинного обучения.
Выбор архитектуры модели
Мы экспериментировали с различными архитектурами моделей машинного обучения, чтобы найти наиболее подходящую для нашей задачи. В конечном итоге, мы остановились на комбинации CRF и RNN. CRF хорошо справляется с моделированием последовательностей, а RNN – с захватом контекста. Эта комбинация позволила нам достичь высокой точности извлечения сущностей.
«Искусственный интеллект не заменит врачей, но врачи, использующие искусственный интеллект, заменят тех, кто его не использует.» ─ Dr. Eric Topol
Примеры работы системы
Вот несколько примеров того, как наша система работает на практике:
Пример 1:
Исходный текст: «У пациента наблюдается повышенное артериальное давление и головная боль. В анамнезе – сахарный диабет 2 типа.»
Результат работы системы:
- Артериальное давление: Симптом
- Головная боль: Симптом
- Сахарный диабет 2 типа: Болезнь
Пример 2:
Исходный текст: «Рекомендовано применение препарата аспирин в дозировке 100 мг в сутки.»
Результат работы системы:
- Аспирин: Лекарственный препарат
- 100 мг: Дозировка
Проблемы и вызовы
Несмотря на наши успехи, мы столкнулись с рядом проблем и вызовов:
- Многозначность терминов: Многие медицинские термины имеют несколько значений, в зависимости от контекста. Например, слово «рак» может означать как конкретный вид рака, так и общее состояние.
- Сокращения и аббревиатуры: В медицинских текстах часто используются сокращения и аббревиатуры, которые могут быть непонятны системе.
- Различные стили письма: Медицинские тексты могут быть написаны в разных стилях, в зависимости от автора и цели текста. Это затрудняет обучение моделей машинного обучения.
Перспективы развития
Мы видим большие перспективы для дальнейшего развития нашей системы:
- Улучшение точности извлечения сущностей: Мы планируем использовать более сложные модели машинного обучения и расширить наши словари и шаблоны.
- Разработка системы разрешения неоднозначности: Мы хотим научить систему понимать контекст и выбирать правильное значение термина.
- Интеграция с другими медицинскими системами: Мы планируем интегрировать нашу систему с электронными медицинскими картами, системами поддержки принятия клинических решений и другими медицинскими системами.
Разработка систем анализа медицинских текстов – это сложная, но очень важная задача. Мы верим, что наша система поможет врачам и исследователям в их работе, сделав медицинскую информацию более доступной и полезной. Мы продолжим развивать нашу систему, чтобы она стала еще более точной, эффективной и полезной для медицинского сообщества.
Подробнее
| Медицинский NER | Извлечение информации из медицинских текстов | Анализ медицинских записей | Обработка естественного языка в медицине | Классификация медицинских сущностей |
|---|---|---|---|---|
| Машинное обучение в медицине | Анализ историй болезни | Автоматическая обработка медицинских текстов | Медицинские термины и онтологии | Извлечение фактов из медицинских документов |