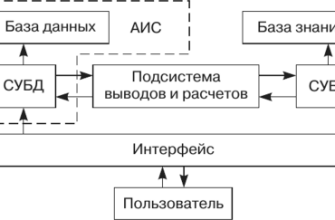
- Расшифровка здоровья: Как мы разрабатываем системы анализа медицинских текстов для извлечения рекомендаций
- Первые шаги: Сбор и подготовка данных
- Выбор модели: От простых алгоритмов к глубокому обучению
- Тонкости внедрения: Адаптация к специфике медицинских текстов
- Извлечение рекомендаций: От выделения сущностей к пониманию контекста
- Оценка результатов: Метрики и экспертная оценка
- Будущее систем анализа медицинских текстов
- Практические примеры использования
Расшифровка здоровья: Как мы разрабатываем системы анализа медицинских текстов для извлечения рекомендаций
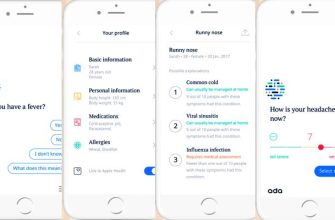
В современном мире, где объемы медицинской информации растут экспоненциально, задача извлечения полезных рекомендаций из огромных массивов текста становится критически важной. Мы, как команда разработчиков, столкнулись с этой проблемой, и наш опыт создания систем анализа медицинских текстов оказался полон интересных вызовов и неожиданных решений. Эта статья – наш личный рассказ о том, как мы погрузились в мир NLP и машинного обучения, чтобы помочь врачам и пациентам принимать более обоснованные решения.
Наш путь начался с осознания масштаба проблемы. Представьте себе врача, которому ежедневно приходится просматривать десятки научных статей, клинических отчетов и историй болезни. В этом море информации легко упустить важные детали, особенно когда речь идет о новых методах лечения или потенциальных побочных эффектах. Именно здесь на помощь приходят системы анализа текста, способные автоматически извлекать ключевую информацию и предоставлять ее в удобном для восприятия формате.
Первые шаги: Сбор и подготовка данных
Любая система машинного обучения начинается с данных. В нашем случае это были медицинские тексты различных типов: научные статьи, клинические протоколы, истории болезни, описания лекарственных препаратов и т.д. Сбор данных – это лишь первый этап, гораздо важнее – их правильная подготовка. Мы столкнулись с рядом проблем:
- Разнородность данных: Тексты были написаны разными стилями, с использованием различной терминологии и в разных форматах.
- Наличие ошибок: Медицинские тексты часто содержат опечатки, сокращения и аббревиатуры, которые необходимо правильно интерпретировать.
- Конфиденциальность: Работа с медицинскими данными требует соблюдения строгих правил конфиденциальности и анонимизации.
Для решения этих проблем мы использовали различные методы предобработки текста, такие как:
- Токенизация: Разделение текста на отдельные слова или фразы.
- Удаление стоп-слов: Исключение из текста наиболее часто встречающихся слов, не несущих смысловой нагрузки (например, «и», «в», «на»).
- Стемминг и лемматизация: Приведение слов к их базовой форме (например, «бегущий» -> «бежать»).
- Нормализация терминологии: Использование медицинских тезаурусов и онтологий для приведения различных терминов к единому стандарту.
Этот этап был, пожалуй, самым трудоемким, но без качественной подготовки данных невозможно добиться хороших результатов в дальнейшем.
Выбор модели: От простых алгоритмов к глубокому обучению
После подготовки данных перед нами встал вопрос о выборе модели машинного обучения. Мы начали с простых алгоритмов, таких как:
- Наивный байесовский классификатор: Простой и быстрый алгоритм, хорошо подходящий для задач классификации текста.
- Метод опорных векторов (SVM): Более сложный алгоритм, способный находить оптимальную разделяющую гиперплоскость между классами.
- Логистическая регрессия: Алгоритм, позволяющий оценивать вероятность принадлежности текста к определенному классу.
Однако, эти алгоритмы показали ограниченную эффективность при работе со сложными медицинскими текстами. Тогда мы решили обратиться к более продвинутым методам – глубокому обучению. В частности, мы экспериментировали с:
- Рекуррентными нейронными сетями (RNN): Модели, хорошо подходящие для обработки последовательностей, таких как текст.
- Трансформерами: Мощные модели, основанные на механизме внимания, позволяющие учитывать контекст при обработке текста.
- BERT и другие предобученные модели: Модели, обученные на огромных массивах текста и способные решать широкий спектр задач NLP.
Использование предобученных моделей, таких как BERT, позволило нам значительно улучшить качество извлечения рекомендаций из медицинских текстов. Эти модели уже содержат богатые знания о языке и мире, что позволяет им более эффективно решать сложные задачи.
Тонкости внедрения: Адаптация к специфике медицинских текстов
Несмотря на мощь современных моделей, просто взять и применить их к медицинским текстам недостаточно. Необходимо адаптировать модели к специфике этой области. Мы столкнулись с рядом проблем:
- Нехватка размеченных данных: Разметка медицинских текстов – сложная и дорогостоящая задача, требующая привлечения квалифицированных специалистов.
- Дисбаланс классов: В медицинских текстах часто встречаются редкие заболевания или побочные эффекты, что приводит к дисбалансу классов и снижает эффективность моделей.
- Необходимость объяснимости: В медицине очень важно понимать, почему модель приняла то или иное решение. «Черный ящик» не подходит для критически важных задач.
Для решения этих проблем мы использовали следующие подходы:
- Аугментация данных: Генерация новых данных на основе существующих с использованием различных техник, таких как замена синонимов или перефразировка предложений.
- Использование синтетических данных: Генерация данных с использованием экспертных знаний или правил.
- Методы объяснимого ИИ (XAI): Использование методов, позволяющих понять, какие факторы повлияли на решение модели.
«Цель науки — не открывать бесконечные двери мудрости, а ставить предел бесконечному заблуждению.» — Бертольд Брехт
Извлечение рекомендаций: От выделения сущностей к пониманию контекста
Основная задача нашей системы – извлечение рекомендаций из медицинских текстов. Это не просто выделение ключевых слов или фраз, а понимание контекста, в котором они используются. Например, необходимо отличать утверждение о том, что «лекарство А эффективно при лечении болезни Б» от утверждения о том, что «лекарство А не эффективно при лечении болезни Б».
Для решения этой задачи мы использовали различные методы NLP, такие как:
- Named Entity Recognition (NER): Выделение именованных сущностей, таких как названия лекарств, заболеваний, симптомов и т.д.
- Relation Extraction (RE): Определение отношений между сущностями, например, «лекарство А» лечит «болезнь Б».
- Sentiment Analysis: Определение тональности текста, например, является ли утверждение положительным, отрицательным или нейтральным.
Комбинируя эти методы, мы смогли создать систему, способную извлекать рекомендации из медицинских текстов с высокой точностью. Важным шагом было создание правил и эвристик, которые позволяли учитывать контекст и отбрасывать ложные срабатывания.
Оценка результатов: Метрики и экспертная оценка
Оценка качества работы системы – важный этап разработки. Мы использовали различные метрики для оценки точности и полноты извлечения рекомендаций, такие как:
- Precision: Доля правильно извлеченных рекомендаций от общего числа извлеченных рекомендаций.
- Recall: Доля правильно извлеченных рекомендаций от общего числа рекомендаций, присутствующих в тексте.
- F1-score: Гармоническое среднее между precision и recall.
Однако, метрики – это лишь часть картины. Важно также проводить экспертную оценку результатов работы системы. Мы привлекали врачей и медицинских работников для оценки качества извлеченных рекомендаций и выявления ошибок. Это позволило нам выявить слабые места системы и внести необходимые улучшения.
Будущее систем анализа медицинских текстов
Мы считаем, что системы анализа медицинских текстов имеют огромный потенциал для улучшения качества медицинской помощи. В будущем эти системы смогут:
- Автоматически анализировать истории болезни и выявлять риски.
- Предоставлять врачам персонализированные рекомендации по лечению.
- Помогать пациентам принимать более обоснованные решения о своем здоровье.
- Ускорять процесс разработки новых лекарств и методов лечения.
Мы продолжаем работать над улучшением нашей системы и верим, что она внесет значительный вклад в развитие медицины.
Практические примеры использования
Чтобы проиллюстрировать возможности нашей системы, приведем несколько практических примеров:
- Анализ научных статей: Система может автоматически извлекать из научных статей информацию о новых методах лечения и их эффективности.
- Анализ клинических протоколов: Система может проверять, соответствуют ли действия врача действующим клиническим протоколам.
- Анализ историй болезни: Система может выявлять риски и предлагать дополнительные обследования или консультации.
Эти примеры показывают, что системы анализа медицинских текстов могут быть полезны как для врачей, так и для пациентов.
Разработка систем анализа медицинских текстов – это сложный и многогранный процесс, требующий глубоких знаний в области NLP, машинного обучения и медицины. Мы прошли долгий путь, полный вызовов и открытий. Наш опыт показывает, что создание таких систем – это не просто техническая задача, а важный шаг на пути к интеллектуальной медицине, где информация становится доступной и полезной для всех.
Подробнее
| LSI Запрос | LSI Запрос | LSI Запрос | LSI Запрос | LSI Запрос |
|---|---|---|---|---|
| NLP в медицине | Машинное обучение в здравоохранении | Анализ медицинских данных | Извлечение информации из медицинских текстов | Автоматическая обработка медицинских текстов |
| Системы поддержки принятия решений в медицине | Анализ историй болезни с помощью ИИ | Извлечение рекомендаций из клинических текстов | Применение BERT в медицине | Медицинская терминология и NLP |