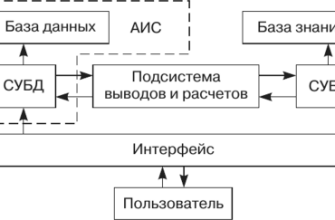
Анализ медицинских текстов: Как мы научили машину выявлять противопоказания и что из этого вышло
Наверное‚ каждый из нас сталкивался с огромными инструкциями к лекарствам‚ написанными сложным медицинским языком. Порой‚ чтобы понять‚ можно ли принимать препарат‚ нужно потратить уйму времени и усилий. А если речь идет о людях с ограниченными возможностями‚ пожилых людях или тех‚ кто просто не имеет медицинского образования? Задача становится практически невыполнимой. Именно поэтому мы решили создать систему‚ которая поможет автоматизировать процесс извлечения противопоказаний из медицинских текстов.
Представьте себе врача‚ которому нужно быстро принять решение о назначении лечения. Ему приходится просматривать множество документов‚ чтобы убедиться‚ что у пациента нет противопоказаний к тому или иному препарату. Ошибка может стоить очень дорого. Наша система призвана помочь врачам принимать более взвешенные решения‚ экономя время и снижая риск врачебных ошибок.
Что такое разработка систем анализа медицинских текстов?
Разработка систем анализа медицинских текстов – это сложный процесс‚ включающий в себя несколько этапов. Прежде всего‚ необходимо собрать и разметить большой объем медицинских текстов‚ таких как инструкции к лекарствам‚ истории болезней‚ научные статьи и т.д. Затем‚ используя методы машинного обучения и обработки естественного языка‚ необходимо обучить модель‚ которая сможет автоматически извлекать из текста нужную информацию‚ в нашем случае – противопоказания.
Этот процесс требует глубоких знаний в области медицины‚ лингвистики и информационных технологий. Мы должны понимать‚ как устроен медицинский язык‚ какие термины используются для обозначения различных заболеваний и состояний‚ и как эти термины связаны между собой. Кроме того‚ необходимо уметь разрабатывать и обучать сложные модели машинного обучения‚ которые смогут эффективно извлекать информацию из текста.
Зачем это нужно?
Вопрос «зачем?» – один из самых важных. Мы живем в эпоху информационного взрыва. Количество медицинских данных растет экспоненциально. Врачи просто физически не могут успевать обрабатывать весь этот объем информации. Автоматизация процесса извлечения противопоказаний позволяет:
- Экономить время врачей: Вместо того‚ чтобы тратить часы на чтение инструкций‚ врачи могут получить информацию о противопоказаниях в считанные секунды.
- Снижать риск врачебных ошибок: Автоматизированная система не устает и не отвлекается‚ поэтому она может более точно выявлять противопоказания.
- Обеспечивать более качественное лечение: Имея доступ к полной и актуальной информации о противопоказаниях‚ врачи могут принимать более взвешенные решения о назначении лечения.
- Улучшать доступность медицинской информации для пациентов: Система может быть использована для создания сервисов‚ которые помогут пациентам самостоятельно получать информацию о противопоказаниях к лекарствам.
Какие методы мы использовали?
Мы использовали комбинацию различных методов машинного обучения и обработки естественного языка. В частности‚ мы применяли:
- Методы извлечения именованных сущностей (Named Entity Recognition‚ NER): Эти методы позволяют автоматически извлекать из текста медицинские термины‚ такие как названия заболеваний‚ лекарств‚ симптомов и т.д.
- Методы классификации текста: Эти методы позволяют классифицировать текст по различным категориям‚ например‚ определить‚ содержит ли текст информацию о противопоказаниях.
- Методы анализа зависимостей: Эти методы позволяют анализировать синтаксическую структуру предложения и выявлять связи между различными словами и словосочетаниями.
- Глубокое обучение (Deep Learning): Мы использовали нейронные сети для обучения модели‚ которая может автоматически извлекать противопоказания из текста.
Каждый из этих методов имеет свои преимущества и недостатки. Мы старались комбинировать их таким образом‚ чтобы получить максимально точный и надежный результат.
Этапы разработки системы
Разработка системы анализа медицинских текстов – это итеративный процесс‚ состоящий из нескольких этапов:
- Сбор данных: Мы собрали большой объем медицинских текстов из различных источников‚ таких как инструкции к лекарствам‚ истории болезней‚ научные статьи и т.д.
- Разметка данных: Мы вручную разметили часть данных‚ указав‚ какие фрагменты текста содержат информацию о противопоказаниях. Эта разметка использовалась для обучения модели машинного обучения.
- Разработка модели: Мы разработали модель машинного обучения‚ которая может автоматически извлекать противопоказания из текста.
- Обучение модели: Мы обучили модель на размеченных данных.
- Оценка модели: Мы оценили качество работы модели на тестовых данных.
- Улучшение модели: Мы улучшили модель‚ основываясь на результатах оценки.
- Внедрение системы: Мы внедрили систему в реальную медицинскую практику.
Каждый этап был критически важен для успеха проекта. Особенно сложным был этап разметки данных‚ так как он требовал большого количества времени и экспертных знаний в области медицины.
«Единственный способ сделать великую работу ― любить то‚ что ты делаешь;» – Стив Джобс
Сложности и вызовы
Разработка системы анализа медицинских текстов сопряжена с рядом сложностей и вызовов:
- Сложность медицинского языка: Медицинский язык характеризуется большим количеством терминов‚ аббревиатур и сокращений‚ что затрудняет его обработку.
- Неоднозначность текста: Один и тот же термин может иметь разные значения в разных контекстах.
- Отсутствие размеченных данных: Разметка медицинских текстов требует больших затрат времени и экспертных знаний.
- Изменчивость данных: Медицинская информация постоянно обновляется‚ поэтому необходимо постоянно переобучать модель.
Мы столкнулись со всеми этими сложностями в процессе разработки нашей системы. Чтобы их преодолеть‚ мы использовали различные методы‚ такие как:
- Использование медицинских словарей и онтологий: Мы использовали медицинские словари и онтологии для расшифровки медицинских терминов и аббревиатур.
- Контекстный анализ: Мы использовали методы контекстного анализа для разрешения неоднозначности текста.
- Активное обучение: Мы использовали методы активного обучения для минимизации объема размеченных данных.
- Непрерывное обучение: Мы использовали методы непрерывного обучения для адаптации модели к изменениям в медицинских данных.
Результаты и перспективы
В результате нашей работы мы создали систему‚ которая может автоматически извлекать противопоказания из медицинских текстов с высокой точностью. Система была протестирована на реальных медицинских данных и показала хорошие результаты.
Мы видим большие перспективы для дальнейшего развития нашей системы. В частности‚ мы планируем:
- Расширить функциональность системы: Мы планируем добавить возможность извлечения другой важной медицинской информации‚ такой как побочные эффекты лекарств‚ дозировки и т.д.
- Улучшить пользовательский интерфейс: Мы планируем сделать пользовательский интерфейс системы более интуитивно понятным и удобным для использования.
- Интегрировать систему с другими медицинскими информационными системами: Мы планируем интегрировать систему с другими медицинскими информационными системами‚ чтобы врачи могли получать информацию о противопоказаниях непосредственно в процессе работы.
Мы верим‚ что наша система может внести значительный вклад в улучшение качества медицинской помощи и повышение безопасности пациентов.
Разработка систем анализа медицинских текстов – это сложная‚ но очень важная задача. Мы надеемся‚ что наш опыт поможет другим исследователям и разработчикам в этой области. Мы продолжим работать над улучшением нашей системы и будем рады сотрудничеству с другими организациями и специалистами.
Мы считаем‚ что будущее медицины – за технологиями‚ которые помогают врачам принимать более взвешенные решения и обеспечивают более качественное лечение. И мы гордимся тем‚ что вносим свой вклад в это будущее.
Подробнее
| LSI Запрос 1 | LSI Запрос 2 | LSI Запрос 3 | LSI Запрос 4 | LSI Запрос 5 |
|---|---|---|---|---|
| Извлечение информации из медицинских текстов | Анализ клинических данных | Обработка естественного языка в медицине | Противопоказания лекарственных средств | Автоматизация медицинских процессов |
| LSI Запрос 6 | LSI Запрос 7 | LSI Запрос 8 | LSI Запрос 9 | LSI Запрос 10 |
| Машинное обучение в здравоохранении | Системы поддержки принятия врачебных решений | Анализ медицинских карт | Извлечение сущностей из биомедицинского текста | Автоматическое выявление побочных эффектов |