- Медицинский Sherlock Holmes: Как мы создавали систему извлечения диагнозов из текстов
- Первые шаги: Определение целей и задач
- Сбор и разметка данных: Самый трудоемкий этап
- Какие инструменты мы использовали для разметки?
- Выбор алгоритмов и моделей машинного обучения
- Предобработка текста: Очистка и нормализация
- Обучение и тестирование модели
- Разработка интерфейса и интеграция с существующими системами
- Какие технологии мы использовали для разработки интерфейса?
Медицинский Sherlock Holmes: Как мы создавали систему извлечения диагнозов из текстов
Приветствую, дорогие читатели! Сегодня мы хотим поделиться с вами захватывающей историей о том, как мы погрузились в мир медицинских текстов и попытались создать своего рода «медицинского Шерлока Холмса» – систему, способную извлекать диагнозы из огромных массивов неструктурированных данных. Это было настоящее приключение, полное вызовов, открытий и, конечно же, бессонных ночей. Мы уверены, что наш опыт будет интересен всем, кто интересуется искусственным интеллектом, обработкой естественного языка и, конечно же, медициной.
Наш путь начался с осознания огромной проблемы: врачи и исследователи тратят колоссальное количество времени на ручной анализ медицинских записей, чтобы выявить закономерности, тенденции и, самое главное, диагнозы. Представьте себе, сколько ценной информации скрыто в этих текстах, и сколько времени и усилий требуется, чтобы её извлечь! Мы решили, что можем помочь, создав автоматизированную систему, которая сделает эту работу быстрее, точнее и эффективнее.
Первые шаги: Определение целей и задач
Прежде чем броситься в омут с головой, нам нужно было четко определить, чего мы хотим достичь. Мы сформулировали следующие цели:
- Создать систему, способную автоматически извлекать диагнозы из медицинских текстов на русском языке.
- Обеспечить высокую точность извлечения, чтобы минимизировать количество ошибок.
- Разработать систему, которая будет легко интегрироваться с существующими медицинскими информационными системами.
- Создать удобный и интуитивно понятный интерфейс для пользователей.
Задачи были не менее амбициозными:
- Собрать и разметить достаточно большой объем медицинских текстов для обучения модели.
- Выбрать подходящие алгоритмы и модели машинного обучения для извлечения информации.
- Разработать эффективные методы предобработки текста для повышения точности извлечения.
- Провести тщательное тестирование и оценку системы.
С таким четким планом в голове мы приступили к работе!
Сбор и разметка данных: Самый трудоемкий этап
Как известно, качество данных – это ключ к успеху любой системы машинного обучения. Поэтому мы уделили особое внимание сбору и разметке медицинских текстов. Мы использовали различные источники, включая электронные медицинские карты, научные статьи и клинические отчеты. Главной проблемой было то, что большинство текстов были неструктурированы и содержали много специфической терминологии.
Разметка данных – это процесс, в ходе которого эксперты вручную отмечают в тексте интересующие нас сущности, в данном случае – диагнозы. Это очень трудоемкий и монотонный процесс, требующий высокой квалификации и внимательности. Мы привлекли к этой работе опытных врачей и лингвистов, которые помогли нам создать качественный размеченный датасет.
Какие инструменты мы использовали для разметки?
Мы перепробовали несколько инструментов для разметки данных, и в итоге остановились на:
- Doccano: Это мощный и удобный инструмент с открытым исходным кодом, который позволяет размечать тексты с использованием различных типов аннотаций.
- Brat: Еще один популярный инструмент для разметки текста, который обладает широкими возможностями кастомизации.
- Самописные скрипты: Для автоматизации некоторых задач разметки мы использовали собственные скрипты на Python.
Выбор алгоритмов и моделей машинного обучения
После того, как у нас появился размеченный датасет, мы приступили к выбору подходящих алгоритмов и моделей машинного обучения. Мы рассматривали различные подходы, включая:
- Conditional Random Fields (CRF): Это классический алгоритм для задач последовательной разметки, который хорошо подходит для извлечения сущностей из текста.
- Recurrent Neural Networks (RNN): RNN, особенно с использованием LSTM или GRU ячеек, хорошо справляются с обработкой последовательностей и могут учитывать контекст слов в предложении.
- Transformers: Трансформеры, такие как BERT и RoBERTa, произвели революцию в области обработки естественного языка и показали отличные результаты во многих задачах, включая извлечение информации.
Предобработка текста: Очистка и нормализация
Предобработка текста – это важный этап, который позволяет улучшить качество данных и повысить точность извлечения информации. Мы использовали следующие методы предобработки:
- Удаление стоп-слов: Мы удалили из текста слова, которые не несут смысловой нагрузки, такие как «и», «в», «на» и т.д.
- Приведение к нижнему регистру: Мы привели все слова к нижнему регистру, чтобы избежать проблем с различием в написании.
- Стемминг и лемматизация: Мы привели слова к их базовой форме, чтобы уменьшить количество вариантов написания одного и того же слова.
- Удаление знаков препинания и специальных символов: Мы удалили из текста знаки препинания и специальные символы, которые не несут полезной информации.
Эти методы позволили нам значительно улучшить качество данных и повысить точность извлечения диагнозов.
Обучение и тестирование модели
После предобработки данных мы приступили к обучению модели. Мы разделили наш размеченный датасет на три части: обучающую, валидационную и тестовую. Обучающая часть использовалась для обучения модели, валидационная – для настройки гиперпараметров, а тестовая – для оценки качества работы модели.
Мы использовали различные метрики для оценки качества работы модели, такие как:
- Precision: Доля правильно извлеченных диагнозов от общего количества извлеченных диагнозов.
- Recall: Доля правильно извлеченных диагнозов от общего количества диагнозов в тексте.
- F1-score: Гармоническое среднее между precision и recall.
Мы постоянно экспериментировали с различными параметрами модели и методами обучения, чтобы добиться наилучших результатов. В итоге нам удалось создать систему, которая демонстрирует высокую точность извлечения диагнозов.
«Искусственный интеллект – это не замена человеческого разума, а его усиление.»
— Рой Амарал
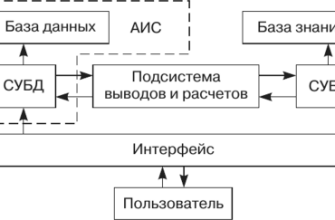
Разработка интерфейса и интеграция с существующими системами
После того, как мы создали модель, способную извлекать диагнозы из текста, нам нужно было сделать её доступной для пользователей. Мы разработали удобный и интуитивно понятный интерфейс, который позволяет пользователям загружать медицинские тексты и получать список извлеченных диагнозов.
Мы также предусмотрели возможность интеграции нашей системы с существующими медицинскими информационными системами. Это позволяет врачам и исследователям использовать нашу систему в своей повседневной работе, не тратя время на переключение между различными приложениями.
Какие технологии мы использовали для разработки интерфейса?
Мы использовали следующие технологии для разработки интерфейса:
- Python: Для разработки серверной части приложения.
- Flask: Для создания веб-API.
Создание системы анализа медицинских текстов и извлечения диагнозов – это сложный, но очень интересный и полезный проект. Мы уверены, что наша система поможет врачам и исследователям быстрее и эффективнее анализировать медицинские данные, что приведет к улучшению качества медицинской помощи.
В будущем мы планируем расширить функциональность нашей системы, добавив поддержку новых языков и типов медицинских документов. Мы также планируем интегрировать нашу систему с другими инструментами анализа данных, чтобы предоставить пользователям еще больше возможностей.
Мы надеемся, что наша история была интересной и полезной для вас. Спасибо за внимание!
Подробнее
| LSI Запрос 1 | LSI Запрос 2 | LSI Запрос 3 | LSI Запрос 4 | LSI Запрос 5 |
|---|---|---|---|---|
| Извлечение информации из медицинских текстов | Анализ медицинских записей с помощью ИИ | Системы обработки естественного языка в медицине | Автоматическое выявление диагнозов из текста | Машинное обучение для медицинских исследований |
| LSI Запрос 6 | LSI Запрос 7 | LSI Запрос 8 | LSI Запрос 9 | LSI Запрос 10 |
| Применение BERT для анализа медицинских текстов | Разработка алгоритмов для извлечения диагнозов | Интеграция систем анализа текста с ЭМК | Использование NLP в клинической практике | Автоматизация анализа медицинских документов |