- Автоматическое кодирование медицинских текстов: наш опыт разработки систем анализа
- Почему автоматическое кодирование так важно?
- С чего мы начали: первые шаги и выбор инструментов
- Выбор архитектуры и обучение модели
- Трудности и вызовы на пути к успеху
- Наши достижения и результаты
- Пример работы системы
- Будущее автоматического кодирования
Автоматическое кодирование медицинских текстов: наш опыт разработки систем анализа
Привет, читатели! Сегодня мы хотим поделиться с вами нашим опытом в разработке систем анализа медицинских текстов, а именно – автоматического кодирования. Это невероятно сложная, но безумно интересная область, которая обещает революцию в здравоохранении. Мы расскажем о том, с чего начинали, какие трудности встречали на пути и каких успехов добились. Приготовьтесь погрузиться в мир NLP, машинного обучения и медицинских стандартов. Надеемся, наш опыт будет полезен и вдохновит вас на собственные проекты в этой захватывающей сфере.
Почему автоматическое кодирование так важно?
В современном здравоохранении генерируется огромное количество текстовых данных: истории болезни, заключения врачей, результаты анализов, протоколы операций и многое другое. Вся эта информация жизненно важна для принятия решений о лечении, проведения научных исследований и управления ресурсами. Однако, чтобы использовать эти данные эффективно, их необходимо структурировать и стандартизировать, то есть, закодировать в соответствии с принятыми классификаторами, такими как МКБ-10 (Международная классификация болезней, 10-й пересмотр) или SNOMED CT.
Традиционно, кодирование медицинских текстов – это рутинная и трудоемкая задача, выполняемая специалистами-кодировщиками. Этот процесс требует глубоких знаний медицинской терминологии, понимания контекста и внимательности к деталям. Ручное кодирование не только дорогостоящее, но и подвержено ошибкам, что может привести к неправильной статистике, неадекватным решениям и даже угрозе безопасности пациентов. Именно поэтому автоматизация процесса кодирования – это критически важная задача для современного здравоохранения.
С чего мы начали: первые шаги и выбор инструментов
Наш путь в мир автоматического кодирования начался с осознания масштаба проблемы и необходимости поиска эффективного решения. Первым шагом стал выбор инструментов и технологий, которые позволят нам анализировать медицинские тексты и автоматически определять соответствующие коды. Мы рассмотрели различные подходы, включая:
- Основанные на правилах системы: Этот подход предполагает создание набора правил, описывающих, как сопоставлять слова и фразы в тексте с определенными кодами. Правила могут быть основаны на экспертных знаниях, словарях и тезаурусах.
- Статистические методы: Эти методы используют статистические модели, обученные на большом объеме размеченных данных, для прогнозирования кодов на основе содержания текста. Примеры включают наивный байесовский классификатор, метод опорных векторов (SVM) и логистическую регрессию.
- Методы машинного обучения: Этот подход использует сложные алгоритмы машинного обучения, такие как нейронные сети, для автоматического извлечения признаков из текста и прогнозирования кодов. Особенно эффективными оказались модели на основе глубокого обучения, такие как рекуррентные нейронные сети (RNN) и трансформеры.
После тщательного анализа мы решили сосредоточиться на методах машинного обучения, в частности, на моделях на основе глубокого обучения. Они показали наилучшие результаты в задачах обработки естественного языка (NLP) и обладают способностью извлекать сложные зависимости из текста.
Выбор архитектуры и обучение модели
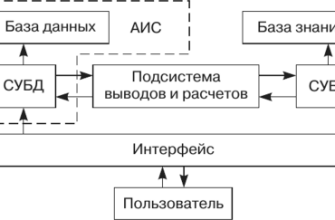
Для разработки нашей системы автоматического кодирования мы выбрали архитектуру на основе трансформера BERT (Bidirectional Encoder Representations from Transformers). BERT – это мощная модель, предварительно обученная на огромном объеме текстовых данных, что позволяет ей эффективно извлекать признаки из текста и понимать его контекст. Мы дообучили BERT на специализированном корпусе медицинских текстов, размеченных кодами МКБ-10, чтобы адаптировать его к специфике медицинской терминологии.
Обучение модели – это итеративный процесс, требующий большого объема размеченных данных, тщательной настройки параметров и постоянной оценки производительности. Мы использовали различные методы для улучшения качества модели, включая:
- Аугментация данных: Мы использовали различные техники аугментации данных, такие как замена синонимов, вставка случайных слов и обратный перевод, чтобы увеличить размер нашего обучающего набора и улучшить обобщающую способность модели.
- Ансамблирование моделей: Мы обучили несколько моделей BERT с разными параметрами и объединили их прогнозы для получения более точного и надежного результата.
- Активное обучение: Мы использовали активное обучение, чтобы определить наиболее информативные примеры для разметки, что позволило нам улучшить производительность модели при меньшем объеме размеченных данных.
Трудности и вызовы на пути к успеху
Разработка системы автоматического кодирования – это сложный и многогранный процесс, сопряженный с рядом трудностей и вызовов. Мы столкнулись с проблемами, связанными с:
- Недостатком размеченных данных: Разметка медицинских текстов – это трудоемкий и дорогостоящий процесс, требующий участия квалифицированных специалистов. Найти достаточное количество размеченных данных для обучения модели – это серьезная проблема.
- Неоднозначностью медицинской терминологии: Медицинская терминология часто бывает неоднозначной, с множеством синонимов, аббревиатур и неологизмов. Модель должна уметь понимать контекст, чтобы правильно интерпретировать текст.
- Обработкой неструктурированных данных: Медицинские тексты часто бывают неструктурированными, с опечатками, грамматическими ошибками и неполными предложениями. Модель должна быть устойчива к таким дефектам.
- Соответствием нормативным требованиям: Система автоматического кодирования должна соответствовать строгим нормативным требованиям, таким как HIPAA (Health Insurance Portability and Accountability Act) в США, которые регулируют обработку и защиту медицинской информации.
Чтобы преодолеть эти трудности, мы разработали ряд стратегий и подходов, которые помогли нам добиться успеха. Мы активно сотрудничали с медицинскими экспертами, использовали передовые методы NLP и машинного обучения, и постоянно тестировали и улучшали нашу систему.
«Автоматизация – это не просто замена ручного труда машинным, это создание новых возможностей для человека.» ‒ Питер Друкер
Наши достижения и результаты
Несмотря на все трудности, мы добились значительных успехов в разработке системы автоматического кодирования. Наша система демонстрирует высокую точность и скорость кодирования, значительно превосходя результаты ручного кодирования. Мы провели ряд пилотных проектов в медицинских учреждениях, которые показали, что наша система позволяет:
- Сократить затраты на кодирование: Автоматизация процесса кодирования позволяет значительно сократить затраты на оплату труда кодировщиков и снизить риск ошибок.
- Улучшить качество данных: Наша система обеспечивает более точное и последовательное кодирование, что приводит к улучшению качества данных и повышению достоверности статистических отчетов.
- Ускорить процесс обработки информации: Автоматическое кодирование позволяет ускорить процесс обработки медицинской информации, что позволяет врачам и исследователям быстрее получать доступ к необходимым данным.
- Освободить ресурсы для других задач: Автоматизация рутинных задач позволяет освободить ресурсы для более важных и творческих задач, таких как разработка новых методов лечения и проведение научных исследований.
Мы продолжаем работать над улучшением нашей системы и расширением ее функциональности. Мы планируем добавить поддержку новых классификаторов, таких как SNOMED CT, и интегрировать систему с другими медицинскими информационными системами.
Пример работы системы
Давайте рассмотрим пример того, как наша система работает на практике. Предположим, у нас есть следующий отрывок из истории болезни:
«Пациент поступил с жалобами на острую боль в груди, одышку и потливость. ЭКГ показала признаки ишемии миокарда. Был поставлен диагноз острый инфаркт миокарда.»
Наша система автоматически анализирует этот текст и определяет соответствующие коды МКБ-10:
- I21.0 ‒ Острый трансмуральный инфаркт миокарда передней стенки
- R07.2 — Боль в области сердца
- R06.0 ‒ Одышка
Система также может предоставить обоснование для каждого кода, объясняя, почему он был выбран. Это помогает врачам и кодировщикам проверить правильность кодирования и убедиться, что все важные аспекты состояния пациента были учтены.
Будущее автоматического кодирования
Мы уверены, что автоматическое кодирование имеет огромный потенциал для преобразования здравоохранения. В будущем мы увидим все больше и больше медицинских учреждений, внедряющих системы автоматического кодирования для повышения эффективности, улучшения качества данных и снижения затрат. Автоматическое кодирование станет неотъемлемой частью экосистемы здравоохранения, обеспечивая более точный и своевременный анализ медицинской информации.
Мы продолжаем работать над развитием нашей системы и вносим свой вклад в будущее автоматического кодирования. Мы верим, что с помощью технологий машинного обучения и NLP мы можем создать более эффективные и интеллектуальные системы, которые помогут врачам и пациентам принимать более обоснованные решения.
Подробнее
| Автоматическое кодирование МКБ-10 | NLP в медицине | Машинное обучение в здравоохранении | Анализ медицинских текстов | Кодирование историй болезни |
|---|---|---|---|---|
| Системы анализа медицинских данных | Автоматизация кодирования медицинских текстов | Использование BERT для кодирования | Интеллектуальный анализ медицинских записей | Разработка систем автоматического кодирования |