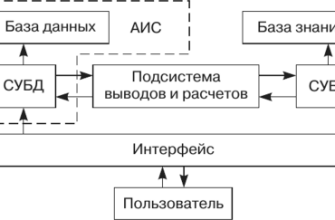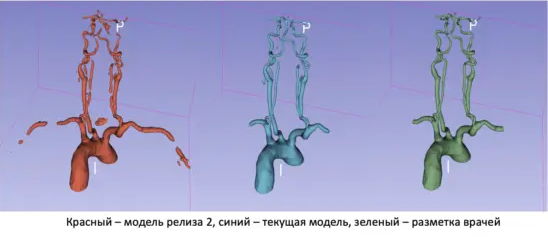
Как мы построили систему анализа медицинских изображений: от сегментации до точности
Приветствую, друзья! Сегодня мы поделимся своим опытом разработки системы анализа медицинских изображений․ Это был долгий и увлекательный путь, полный вызовов и открытий․ Мы расскажем о каждом этапе, начиная с выбора инструментов и заканчивая оптимизацией точности․ Надеемся, наш опыт будет полезен тем, кто только начинает свой путь в этой захватывающей области․
В мире, где технологии проникают во все сферы нашей жизни, медицина не остаётся в стороне․ Автоматизация анализа медицинских изображений – это не просто модный тренд, это насущная необходимость․ Она позволяет врачам быстрее и точнее ставить диагнозы, а значит, спасать больше жизней․ Именно это осознание и подтолкнуло нас к созданию нашей системы․
Выбор инструментов и технологий
Первый шаг – это выбор подходящих инструментов и технологий․ Мы перебрали множество вариантов, прежде чем остановиться на тех, которые лучше всего соответствовали нашим требованиям․ Важно было учесть не только функциональность, но и масштабируемость, надежность и стоимость․
Наш выбор пал на Python как основной язык программирования, благодаря его богатой экосистеме библиотек для машинного обучения и обработки изображений․ Для сегментации изображений мы использовали библиотеки OpenCV и SimpleITK․ Для построения моделей машинного обучения выбрали TensorFlow и Keras, как наиболее гибкие и мощные фреймворки․ А для хранения данных остановились на базе данных PostgreSQL․
Этапы разработки
Разработка системы анализа медицинских изображений – это многоэтапный процесс, требующий внимательного планирования и координации․ Мы разбили проект на несколько ключевых этапов, чтобы упростить управление и контроль․
Сбор и подготовка данных
Первый и, пожалуй, самый важный этап – это сбор и подготовка данных․ Без качественных данных невозможно построить эффективную систему машинного обучения․ Мы собирали данные из различных источников, включая больницы и исследовательские институты․ Важно было обеспечить конфиденциальность и анонимность пациентов․
После сбора данных необходимо было их очистить и подготовить к обучению․ Это включало удаление шумов, коррекцию контрастности и нормализацию изображений․ Также мы вручную разметили часть данных, чтобы использовать их для обучения с учителем;
Сегментация изображений
Сегментация изображений – это процесс разделения изображения на отдельные области, представляющие интерес․ В нашем случае это были, например, опухоли на рентгеновских снимках или участки поражения на КТ․
Мы использовали несколько подходов к сегментации, включая классические методы на основе пороговой обработки и морфологических операций, а также более современные методы на основе глубокого обучения, такие как U-Net․ U-Net показала себя особенно хорошо, позволяя достичь высокой точности сегментации․
Обучение моделей машинного обучения
После сегментации изображений мы приступили к обучению моделей машинного обучения․ Целью было научить модель автоматически обнаруживать и классифицировать различные патологии на медицинских изображениях․
Мы экспериментировали с различными архитектурами нейронных сетей, включая сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN)․ CNN оказались наиболее эффективными для анализа изображений, позволяя извлекать важные признаки из изображений и классифицировать их․
Оценка и оптимизация точности
Оценка и оптимизация точности – это непрерывный процесс, требующий постоянного мониторинга и улучшения․ Мы использовали различные метрики для оценки точности, включая точность, полноту, F1-меру и AUC-ROC․
Чтобы повысить точность, мы применяли различные методы, такие как увеличение данных, регуляризация и ансамблирование моделей․ Также мы проводили анализ ошибок, чтобы выявить слабые места в нашей системе и исправить их․
«Единственный способ делать великую работу – любить то, что ты делаешь․» ⎻ Стив Джобс
Проблемы и решения
В процессе разработки мы столкнулись с рядом проблем, которые потребовали творческого подхода и нестандартных решений․ Одной из главных проблем была нехватка данных․ Медицинские данные часто являются конфиденциальными и труднодоступными․
Чтобы решить эту проблему, мы использовали методы увеличения данных, такие как повороты, масштабирование и добавление шума․ Также мы сотрудничали с другими исследовательскими группами, чтобы обмениваться данными и опытом․
Еще одной проблемой была высокая вычислительная сложность моделей глубокого обучения․ Обучение таких моделей требует больших вычислительных ресурсов и времени․ Чтобы решить эту проблему, мы использовали облачные вычисления и распределенное обучение․
Результаты и перспективы
В результате нашей работы мы создали систему анализа медицинских изображений, которая позволяет автоматически обнаруживать и классифицировать различные патологии с высокой точностью․ Система может использоваться врачами для диагностики и планирования лечения․
Мы продолжаем работать над улучшением нашей системы․ В будущем мы планируем добавить поддержку новых типов изображений и патологий, а также интегрировать систему с другими медицинскими информационными системами․
Разработка системы анализа медицинских изображений – это сложная, но очень важная задача․ Она требует знаний в области машинного обучения, обработки изображений и медицины․ Но результаты стоят затраченных усилий․ Автоматизация анализа медицинских изображений может помочь врачам быстрее и точнее ставить диагнозы, а значит, спасать больше жизней․ Мы надеемся, что наш опыт будет полезен тем, кто только начинает свой путь в этой захватывающей области․
Подробнее
| Анализ рентгеновских снимков | Сегментация медицинских изображений | Машинное обучение в медицине | Диагностика по изображениям | Точность анализа изображений |
|---|---|---|---|---|
| Обработка медицинских данных | Автоматизация диагностики | Искусственный интеллект в здравоохранении | Глубокое обучение для медицинских изображений | Распознавание патологий на снимках |