- DICOM: От пикселя к диагнозу – Как мы разрабатываем системы анализа медицинских изображений
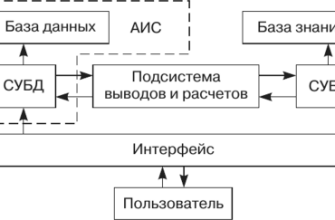
- Что такое DICOM и почему это важно?
- Ключевые компоненты DICOM:
- Наш путь в разработке систем анализа DICOM
- Этапы разработки:
- Технологии и инструменты, которые мы используем
- Предобработка медицинских изображений: Искусство улучшения видимости
- Сегментация: Выделение ключевых областей интереса
- Машинное обучение в анализе медицинских изображений
- Проблемы и вызовы в разработке систем анализа DICOM
- Будущее анализа медицинских изображений
DICOM: От пикселя к диагнозу – Как мы разрабатываем системы анализа медицинских изображений
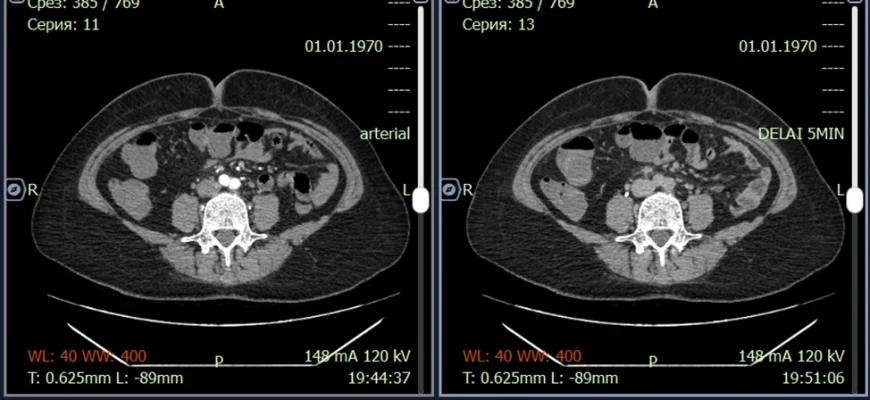
В эпоху цифровой медицины, когда изображения стали неотъемлемой частью диагностики, разработка систем анализа медицинских изображений играет критически важную роль. Мы, как команда разработчиков, погрузились в мир DICOM (Digital Imaging and Communications in Medicine) – международного стандарта для хранения, передачи и визуализации медицинских изображений. Наш опыт показывает, что это не просто задача кодирования, а настоящее искусство интерпретации визуальной информации для помощи врачам в постановке точных диагнозов.
Путь от получения изображения до получения значимой информации – это сложный процесс, требующий глубоких знаний в области обработки изображений, машинного обучения и, конечно же, медицины. В этой статье мы поделимся нашим опытом, расскажем о сложностях, с которыми мы сталкивались, и решениях, которые мы находили, чтобы создать эффективные и надежные системы анализа медицинских изображений.
Что такое DICOM и почему это важно?
DICOM – это больше, чем просто формат файла. Это целый протокол, определяющий, как медицинские изображения и связанная с ними информация должны быть структурированы, переданы и отображены. Этот стандарт позволяет различным медицинским устройствам и программному обеспечению взаимодействовать друг с другом, обеспечивая беспрепятственный обмен данными между больницами, клиниками и врачами.
Представьте себе, что каждое медицинское устройство (рентген, МРТ, КТ) использует свой собственный формат изображений. Обмен информацией между ними был бы невозможен, что привело бы к огромным задержкам и ошибкам в диагностике. DICOM решает эту проблему, стандартизируя формат и протоколы обмена данными. Это как универсальный язык, понятный всем медицинским устройствам.
Ключевые компоненты DICOM:
- Формат файла: Структура хранения изображения и метаданных.
- Протокол передачи: Способ обмена данными между устройствами.
- Словари данных: Стандартизированные термины для описания изображений и пациентов.
Наш путь в разработке систем анализа DICOM
Когда мы только начинали разрабатывать системы анализа медицинских изображений, мы столкнулись с рядом вызовов. DICOM – это сложный стандарт, и его понимание требует времени и усилий. Кроме того, медицинские изображения часто имеют низкое качество, шум и артефакты, что затрудняет их анализ.
Мы начали с изучения спецификаций DICOM и экспериментов с различными библиотеками и инструментами для работы с медицинскими изображениями. Мы также консультировались с врачами и экспертами в области медицинской визуализации, чтобы лучше понять их потребности и требования.
Этапы разработки:
- Получение и декодирование DICOM-изображений: Извлечение пиксельных данных и метаданных.
- Предобработка изображений: Удаление шума, коррекция контрастности и другие методы улучшения качества изображения.
- Сегментация: Выделение интересующих областей (например, опухолей) на изображении.
- Извлечение признаков: Вычисление характеристик выделенных областей (например, размер, форма, текстура).
- Классификация: Использование машинного обучения для определения типа заболевания или состояния.
- Визуализация результатов: Отображение результатов анализа на изображении или в виде отчета.
Технологии и инструменты, которые мы используем
Для разработки систем анализа медицинских изображений мы используем широкий спектр технологий и инструментов, включая:
- Языки программирования: Python, C++, Java
- Библиотеки обработки изображений: OpenCV, scikit-image
- Фреймворки машинного обучения: TensorFlow, PyTorch
- DICOM-библиотеки: pydicom, DCMTK
- Инструменты визуализации: VTK, ITK
Мы также используем облачные платформы, такие как Amazon Web Services (AWS) и Google Cloud Platform (GCP), для хранения и обработки больших объемов данных медицинских изображений.
Предобработка медицинских изображений: Искусство улучшения видимости
Медицинские изображения, полученные с помощью различных методов визуализации (рентген, КТ, МРТ), зачастую страдают от шума, низкой контрастности и артефактов. Предобработка играет решающую роль в улучшении качества изображений, делая их более пригодными для анализа и интерпретации.
Мы используем различные методы предобработки, в зависимости от типа изображения и конкретной задачи. Некоторые из наиболее распространенных методов включают:
- Фильтрация шума: Медианный фильтр, гауссовский фильтр.
- Коррекция контрастности: Гистограммное выравнивание, CLAHE (Contrast Limited Adaptive Histogram Equalization).
- Удаление артефактов: Алгоритмы, специфичные для конкретного типа артефактов.
- Нормализация: Приведение интенсивности пикселей к определенному диапазону.
Правильная предобработка может значительно улучшить результаты сегментации и классификации, что в конечном итоге приводит к более точной диагностике.
Сегментация: Выделение ключевых областей интереса
Сегментация – это процесс разделения изображения на несколько регионов, соответствующих различным объектам или структурам. В контексте медицинских изображений, сегментация используется для выделения органов, опухолей, кровеносных сосудов и других областей, представляющих интерес для врача.
Мы используем как традиционные методы сегментации, так и методы, основанные на глубоком обучении. Традиционные методы, такие как пороговая обработка, выделение границ и кластеризация, могут быть эффективны для простых задач сегментации. Однако для более сложных задач, таких как сегментация опухолей с нечеткими границами, методы глубокого обучения показывают лучшие результаты.
Мы используем различные архитектуры глубоких нейронных сетей для сегментации медицинских изображений, включая:
- U-Net: Архитектура, специально разработанная для сегментации медицинских изображений.
- Mask R-CNN: Архитектура для обнаружения и сегментации объектов.
- V-Net: Архитектура для сегментации объемных медицинских изображений.
«Будущее принадлежит тем, кто верит в красоту своей мечты.» ⎻ Элеонора Рузвельт
Машинное обучение в анализе медицинских изображений
Машинное обучение стало мощным инструментом в анализе медицинских изображений. Алгоритмы машинного обучения могут быть обучены на больших наборах данных медицинских изображений, чтобы автоматически обнаруживать заболевания, оценивать их тяжесть и прогнозировать исход лечения.
Мы используем различные алгоритмы машинного обучения для решения различных задач анализа медицинских изображений, включая:
- Классификация: Определение типа заболевания (например, рак легких, пневмония).
- Обнаружение: Обнаружение аномалий (например, опухолей, кровоизлияний).
- Регрессия: Оценка размера опухоли, степени стеноза сосуда;
- Сегментация: Выделение областей интереса (см. предыдущий раздел).
Мы используем как традиционные алгоритмы машинного обучения, такие как логистическая регрессия, SVM (Support Vector Machines) и случайный лес, так и методы глубокого обучения, такие как сверточные нейронные сети (CNN). Глубокое обучение особенно эффективно для задач, требующих обработки больших объемов данных и выявления сложных закономерностей.
Проблемы и вызовы в разработке систем анализа DICOM
Разработка систем анализа медицинских изображений – это сложная задача, требующая решения ряда проблем и вызовов. Некоторые из наиболее распространенных проблем включают:
- Недостаток данных: Для обучения эффективных алгоритмов машинного обучения требуются большие наборы данных медицинских изображений, которые часто трудно получить из-за соображений конфиденциальности и регуляторных ограничений.
- Разнообразие данных: Медицинские изображения могут значительно различаться в зависимости от оборудования, протоколов сканирования и пациентов, что затрудняет создание универсальных алгоритмов.
- Интерпретируемость: Алгоритмы глубокого обучения часто являются «черными ящиками», что затрудняет понимание того, как они принимают решения. Это может быть проблемой в медицинских приложениях, где важно понимать причины, лежащие в основе диагноза.
- Регуляторные требования: Разработка и внедрение медицинских устройств и программного обеспечения регулируются строгими правилами, которые необходимо соблюдать.
Мы решаем эти проблемы, используя различные стратегии, включая:
- Аугментация данных: Использование методов увеличения набора данных, таких как повороты, масштабирование и добавление шума, для улучшения обобщающей способности алгоритмов машинного обучения.
- Перенос обучения: Использование моделей, предварительно обученных на больших наборах данных изображений, для ускорения обучения и улучшения производительности на меньших наборах данных медицинских изображений.
- Разработка интерпретируемых моделей: Использование методов визуализации и объяснения, чтобы понять, как алгоритмы машинного обучения принимают решения.
- Соблюдение регуляторных требований: Работа в соответствии с применимыми правилами и стандартами, такими как HIPAA (Health Insurance Portability and Accountability Act) и GDPR (General Data Protection Regulation).
Будущее анализа медицинских изображений
Анализ медицинских изображений – это быстро развивающаяся область, которая имеет огромный потенциал для улучшения диагностики, лечения и профилактики заболеваний. Мы видим будущее анализа медицинских изображений в следующих направлениях:
- Более точная и ранняя диагностика: Алгоритмы машинного обучения смогут обнаруживать заболевания на ранних стадиях, когда они более поддаются лечению.
- Персонализированная медицина: Анализ медицинских изображений позволит адаптировать лечение к индивидуальным потребностям каждого пациента.
- Автоматизация рутинных задач: Алгоритмы смогут автоматизировать рутинные задачи, такие как измерение размера опухоли и подсчет клеток, освобождая врачей для более сложных задач.
- Удаленный мониторинг: Анализ медицинских изображений позволит проводить удаленный мониторинг состояния пациентов, что особенно важно для пациентов, живущих в отдаленных районах.
Мы гордимся тем, что участвуем в этой захватывающей области и вносим свой вклад в улучшение здоровья людей.
Подробнее
| Анализ медицинских изображений | DICOM стандарт | Машинное обучение в медицине | Сегментация медицинских изображений | Предобработка DICOM |
|---|---|---|---|---|
| Разработка AI для медицины | Классификация медицинских изображений | Обнаружение патологий на изображениях | Deep Learning в медицинской визуализации | Автоматизированный анализ DICOM |