- Медицинские данные: лабиринт сбора и разметки, или как мы не заблудились
- Сбор медицинских данных: поиск сокровищ в цифровом море
- Проблемы конфиденциальности и анонимизации
- Разнообразие форматов и источников данных
- Разметка медицинских данных: искусство превращения хаоса в порядок
- Поиск квалифицированных аннотаторов
- Обеспечение согласованности и точности разметки
- Инструменты и платформы для разметки данных
- Уроки, которые мы извлекли
- Будущее сбора и разметки медицинских данных
Медицинские данные: лабиринт сбора и разметки, или как мы не заблудились
Мы, как и многие исследователи и разработчики в сфере здравоохранения, постоянно сталкиваемся с необходимостью использования медицинских данных. Без них невозможно строить эффективные модели машинного обучения, разрабатывать новые методы диагностики и лечения, а также улучшать качество медицинского обслуживания в целом. Но, как мы быстро поняли, сбор и разметка этих данных — это не просто задача, это целое приключение, полное неожиданных поворотов и сложных препятствий.
В этой статье мы поделимся нашим личным опытом преодоления трудностей, связанных с получением и обработкой медицинских данных. Мы расскажем о проблемах, с которыми столкнулись, о решениях, которые нашли, и о уроках, которые извлекли. Надеемся, наш опыт будет полезен и вам, и поможет избежать многих ошибок на этом непростом пути.
Сбор медицинских данных: поиск сокровищ в цифровом море
Первая проблема, с которой мы столкнулись, — это доступ к самим данным. Медицинская информация является строго конфиденциальной и защищена различными нормативными актами, такими как HIPAA (в США) и GDPR (в Европе). Получить доступ к данным пациентов не так просто, как может показаться на первый взгляд. Необходимо соблюдать множество юридических и этических требований, чтобы не нарушить права пациентов и не подвергнуть себя риску штрафов и судебных разбирательств.
Мы начали с изучения существующих баз данных и репозиториев медицинских данных. К нашему удивлению, обнаружили, что многие из них либо недоступны для нас, либо содержат неполные или устаревшие данные. Кроме того, даже если данные доступны, они часто представлены в различных форматах и структурах, что затрудняет их интеграцию и анализ.
Проблемы конфиденциальности и анонимизации
Одной из главных проблем при работе с медицинскими данными является необходимость соблюдения конфиденциальности пациентов. Любая информация, которая может идентифицировать пациента, должна быть удалена или анонимизирована. Этот процесс может быть сложным и трудоемким, особенно если данные содержат текстовые записи, изображения или аудиозаписи.
Мы использовали различные методы анонимизации, такие как удаление идентифицирующей информации, замена ее псевдонимами и агрегация данных. Однако, даже после анонимизации, всегда существует риск того, что данные могут быть деидентифицированы с использованием других источников информации. Поэтому мы уделяли особое внимание выбору методов анонимизации и постоянно оценивали риск деидентификации.
Разнообразие форматов и источников данных
Медицинские данные поступают из различных источников и представлены в различных форматах. Это могут быть электронные медицинские записи (EMR), результаты лабораторных исследований, изображения (рентгеновские снимки, МРТ, КТ), аудиозаписи (например, записи консультаций с врачом) и даже данные, собранные с помощью носимых устройств.
Каждый из этих источников данных имеет свои особенности и требует специальных методов обработки. Например, для обработки текстовых записей мы использовали методы обработки естественного языка (NLP), а для обработки изображений — методы компьютерного зрения. Нам пришлось разработать собственные инструменты и скрипты для преобразования данных из различных форматов в единый формат, пригодный для анализа.
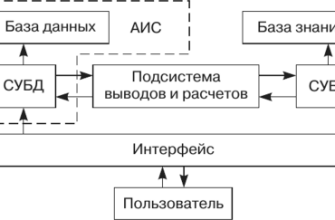
Разметка медицинских данных: искусство превращения хаоса в порядок
После того, как мы получили доступ к данным, следующей задачей стала их разметка. Разметка данных — это процесс присвоения меток или аннотаций к данным, чтобы сделать их понятными для алгоритмов машинного обучения. Например, мы могли размечать рентгеновские снимки, указывая на них области, содержащие признаки заболевания, или размечать текстовые записи, выделяя в них ключевые слова и фразы.
Разметка медицинских данных — это трудоемкий и дорогостоящий процесс, требующий высокой квалификации и опыта. Медицинские данные часто содержат сложные и неоднозначные случаи, требующие экспертной оценки. Кроме того, разметка данных должна быть согласованной и точной, чтобы обеспечить высокое качество обучения моделей машинного обучения.
Поиск квалифицированных аннотаторов
Одной из главных проблем при разметке медицинских данных является поиск квалифицированных аннотаторов. Аннотаторы должны обладать глубокими знаниями в области медицины и понимать специфику размечаемых данных. Например, для разметки рентгеновских снимков необходимы врачи-рентгенологи, а для разметки текстовых записей — врачи-терапевты или медицинские эксперты.
Мы столкнулись с тем, что найти достаточное количество квалифицированных аннотаторов, готовых работать над проектом разметки данных, было непросто. Мы использовали различные стратегии поиска аннотаторов, такие как сотрудничество с медицинскими учреждениями, размещение объявлений на специализированных платформах и привлечение студентов-медиков.
Обеспечение согласованности и точности разметки
Чтобы обеспечить высокое качество разметки данных, необходимо обеспечить согласованность и точность работы аннотаторов. Согласованность означает, что разные аннотаторы должны размечать одни и те же данные одинаково. Точность означает, что разметка должна соответствовать истинному состоянию вещей.
Мы использовали различные методы для обеспечения согласованности и точности разметки. Во-первых, мы разработали подробные инструкции и руководства для аннотаторов. Во-вторых, мы проводили регулярные тренинги и обсуждения с аннотаторами, чтобы убедиться, что они понимают инструкции и правильно применяют их на практике. В-третьих, мы использовали методы контроля качества, такие как проверка разметки несколькими аннотаторами и сравнение их результатов.
«Информация ⎼ это кислород современной эпохи. Кто владеет информацией, тот владеет миром.» ─ Натан Ротшильд
Инструменты и платформы для разметки данных
Существует множество инструментов и платформ для разметки данных, как коммерческих, так и с открытым исходным кодом. Выбор подходящего инструмента зависит от типа данных, требований к разметке и бюджета проекта.
Мы использовали различные инструменты для разметки данных, такие как Labelbox, Prodigy и VGG Image Annotator (VIA). Каждый из этих инструментов имеет свои преимущества и недостатки. Labelbox, это мощная коммерческая платформа, предлагающая широкий набор функций и интеграций. Prodigy — это гибкий инструмент с открытым исходным кодом, который можно настроить под свои нужды. VIA — это простой и удобный инструмент для разметки изображений.
Уроки, которые мы извлекли
Работа с медицинскими данными — это сложный и многогранный процесс, требующий знаний, опыта и терпения. Мы извлекли много ценных уроков на этом пути. Вот некоторые из них:
- Начинайте с малого: Не пытайтесь сразу охватить все данные. Начните с небольшого набора данных и постепенно расширяйте его.
- Планируйте заранее: Тщательно спланируйте процесс сбора и разметки данных, прежде чем начинать работу. Определите цели проекта, выберите подходящие инструменты и методы, и разработайте подробные инструкции для аннотаторов.
- Уделяйте внимание качеству данных: Качество данных — это ключ к успеху. Убедитесь, что данные чистые, полные и точные.
- Сотрудничайте с экспертами: Сотрудничайте с медицинскими экспертами, чтобы получить их консультации и помощь в разметке данных.
- Автоматизируйте, где это возможно: Используйте инструменты автоматизации, чтобы ускорить и упростить процесс сбора и разметки данных.
- Не забывайте об этике: Всегда помните об этических аспектах работы с медицинскими данными и соблюдайте конфиденциальность пациентов.
Будущее сбора и разметки медицинских данных
Мы уверены, что будущее сбора и разметки медицинских данных связано с автоматизацией и машинным обучением. Разрабатываются новые алгоритмы и инструменты, которые позволяют автоматически собирать, обрабатывать и размечать медицинские данные. Это позволит значительно ускорить и удешевить процесс разработки новых медицинских технологий и улучшить качество медицинского обслуживания в целом.
Например, разрабатываются алгоритмы, которые могут автоматически обнаруживать признаки заболевания на рентгеновских снимках или анализировать текстовые записи пациентов, чтобы выявлять факторы риска и предсказывать развитие заболеваний. Эти алгоритмы могут быть использованы для автоматической разметки данных, что значительно сократит время и затраты на разметку.
Сбор и разметка медицинских данных, это сложная, но важная задача. Без качественных медицинских данных невозможно разрабатывать новые методы диагностики и лечения, а также улучшать качество медицинского обслуживания. Мы надеемся, что наш опыт будет полезен и вам, и поможет избежать многих ошибок на этом непростом пути. Мы верим, что будущее медицины связано с использованием больших данных и машинного обучения, и мы готовы внести свой вклад в это будущее.
Подробнее
| LSI Запрос 1 | LSI Запрос 2 | LSI Запрос 3 | LSI Запрос 4 | LSI Запрос 5 |
|---|---|---|---|---|
| Этика сбора медицинских данных | Анонимизация медицинских данных | Разметка медицинских изображений | NLP в медицине | Инструменты для разметки данных |
| LSI Запрос 6 | LSI Запрос 7 | LSI Запрос 8 | LSI Запрос 9 | LSI Запрос 10 |
| Конфиденциальность данных пациентов | Квалифицированные аннотаторы для медицины | Автоматизация разметки данных | Проблемы качества медицинских данных | Нормативные акты в сфере медицинских данных |