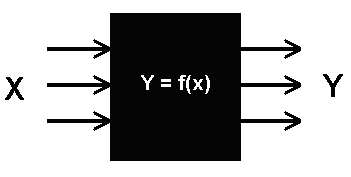
- Внутри «Черного Ящика»: Почему Понимание AI Важнее Его Мощи
- Что такое «Черный Ящик» в контексте AI?
- Почему Интерпретируемость Так Важна?
- Примеры Проблем, Связанных с «Черными Ящиками»
- Методы для «Открытия» Черного Ящика
- Применение Интерпретируемого AI на практике
- Будущее Интерпретируемого AI
- Вызовы и Перспективы
Внутри «Черного Ящика»: Почему Понимание AI Важнее Его Мощи
Мы живем в эпоху, когда искусственный интеллект (AI) проникает во все сферы нашей жизни. От рекомендаций фильмов до медицинских диагнозов, AI-системы принимают решения, которые оказывают существенное влияние на нашу жизнь. Но что происходит, когда мы не понимаем, как эти решения принимаються? Именно здесь возникает проблема «черного ящика».
Представьте себе: вам отказывают в кредите, и единственное объяснение – «так решил алгоритм». Или, еще страшнее, автономный автомобиль попадает в аварию, и никто не может объяснить, почему он принял именно такое решение. Эти сценарии, хоть и кажутся футуристическими, становятся все более реальными с развитием сложных моделей машинного обучения, таких как глубокие нейронные сети.
Что такое «Черный Ящик» в контексте AI?
Термин «черный ящик» относится к системам, чьи внутренние процессы непрозрачны и труднообъяснимы. В контексте AI это означает, что мы можем видеть входные данные (например, изображение кошки) и выходные данные (AI идентифицирует кошку), но не понимать, как AI пришел к этому выводу. Это особенно актуально для сложных нейронных сетей с миллионами параметров, где логика принятия решений распределена по множеству слоев и связей.
Проблема не в том, что AI намеренно скрывает свои процессы, а в том, что эти процессы настолько сложны, что их трудно понять даже самим разработчикам. Это все равно, что пытаться разобраться в работе человеческого мозга, наблюдая за его активностью на МРТ. Мы можем видеть, какие области активируются, но не понимать, какие мысли и чувства лежат в основе этой активности.
Почему Интерпретируемость Так Важна?
Интерпретируемость – это способность понимать, как AI-система принимает решения. Это не просто академический интерес, а критически важный аспект для доверия, ответственности и безопасности AI.
- Доверие: Мы с большей вероятностью будем доверять AI-системе, если понимаем, как она работает. Если AI ставит диагноз, мы хотим знать, на каких данных он основан. Если AI рекомендует инвестиции, мы хотим понимать, какие факторы он учитывает.
- Ответственность: Когда AI совершает ошибку, важно понимать, почему это произошло, чтобы исправить проблему и предотвратить ее повторение. Если автономный автомобиль сбивает пешехода, необходимо выяснить, какая ошибка в алгоритме привела к этому трагическому исходу.
- Безопасность: «Черные ящики» могут быть уязвимы для атак и манипуляций. Если мы не понимаем, как работает AI, мы не можем предвидеть, как его можно обмануть или использовать во вред.
Примеры Проблем, Связанных с «Черными Ящиками»
Давайте рассмотрим несколько конкретных примеров, чтобы проиллюстрировать проблемы, связанные с непрозрачностью AI:
- Предвзятость: AI-системы обучаются на данных, и если эти данные содержат предвзятости, AI может их унаследовать и усилить. Например, система распознавания лиц, обученная на изображениях преимущественно белых лиц, может хуже распознавать лица людей с другим цветом кожи.
- Переобучение: AI может «переобучиться» на тренировочных данных, то есть запомнить их наизусть, а не научиться обобщать. В этом случае AI будет отлично работать на тренировочных данных, но плохо на новых, незнакомых данных.
- Необъяснимые решения: AI может принимать решения, которые кажутся нелогичными или противоречивыми. Например, система кредитного скоринга может отказать в кредите человеку с хорошей кредитной историей, не объясняя причин.
«Объяснимый AI – это не просто хорошо; это необходимо для ответственного использования AI в нашем обществе.» ⎯ Цитата неизвестного эксперта по AI
Методы для «Открытия» Черного Ящика
К счастью, исследователи и разработчики активно работают над методами, которые позволяют сделать AI более интерпретируемым. Вот некоторые из них:
- LIME (Local Interpretable Model-agnostic Explanations): Этот метод объясняет решения AI, аппроксимируя его локально более простой, интерпретируемой моделью.
- SHAP (SHapley Additive exPlanations): Этот метод использует теорию игр для оценки вклада каждого признака в решение AI.
- Grad-CAM (Gradient-weighted Class Activation Mapping): Этот метод визуализирует, какие части изображения AI использует для принятия решения.
- Attention Mechanisms: В нейронных сетях механизмы внимания позволяют AI выделять наиболее важные части входных данных, делая процесс принятия решений более прозрачным.
- Разработка более простых моделей: Иногда лучше использовать более простую модель, которую легче понять, чем пытаться объяснить сложную модель.
Применение Интерпретируемого AI на практике
Интерпретируемый AI уже находит применение в различных областях:
| Область | Пример | Преимущества |
|---|---|---|
| Медицина | AI помогает врачам ставить диагнозы, объясняя, какие факторы он учитывал. | Повышает доверие к AI, помогает врачам принимать более обоснованные решения. |
| Финансы | AI оценивает риски при выдаче кредитов, объясняя, почему он принял то или иное решение; | Обеспечивает справедливость и прозрачность при принятии финансовых решений. |
| Право | AI помогает юристам анализировать судебные дела, выделяя наиболее важные прецеденты. | Ускоряет процесс анализа и повышает точность. |
Будущее Интерпретируемого AI
Интерпретируемость AI – это не просто модное слово, а необходимое условие для его широкого распространения и ответственного использования. В будущем мы увидим все больше и больше разработок в этой области, направленных на то, чтобы сделать AI более понятным и прозрачным.
Нам, как пользователям и разработчикам AI, необходимо требовать от AI-систем объяснений их решений. Мы должны задавать вопросы, критически оценивать результаты и не бояться сомневаться в «черных ящиках». Только так мы сможем создать AI, который будет служить нам, а не наоборот.
Вызовы и Перспективы
Несмотря на значительный прогресс, интерпретируемость AI остается сложной задачей. Существует компромисс между точностью и интерпретируемостью – более сложные модели часто более точны, но менее понятны. Кроме того, разные люди могут требовать разных уровней объяснения. Врачу может понадобиться детальное объяснение, в то время как обычному пользователю достаточно общего понимания.
Однако, мы уверены, что эти вызовы будут преодолены. Развитие новых методов, стандартов и регуляций позволит нам создать AI, который будет одновременно мощным, надежным и понятным. Будущее за интерпретируемым AI.
Подробнее
| Объяснимый AI | Интерпретируемость машинного обучения | Прозрачность алгоритмов | Доверие к искусственному интеллекту | Ответственный AI |
|---|---|---|---|---|
| Методы объяснения AI | Проблемы черного ящика AI | Применение интерпретируемого AI | Предвзятость в AI | Безопасность AI систем |