Машинное обучение для предсказания смертности: наш опыт
В современном мире, где данные стали новой нефтью, машинное обучение (МО) открывает невероятные возможности в самых разных областях. Одной из самых важных и чувствительных является здравоохранение, где алгоритмы МО могут помочь спасать жизни. В этой статье мы поделимся нашим опытом использования машинного обучения для предсказания смертности, расскажем о сложностях, успехах и уроках, которые мы извлекли.
Наш путь начался с осознания огромного потенциала, который скрывается в медицинских данных. Больницы и клиники накапливают огромные объемы информации о пациентах: результаты анализов, история болезней, данные о приемах лекарств и многое другое. Если правильно обработать и проанализировать эти данные, можно выявить закономерности, которые помогут предсказать риск развития серьезных заболеваний и, в конечном итоге, снизить смертность. Но как это сделать на практике?
Постановка задачи и выбор данных
Первым шагом стало четкое определение задачи. Мы решили сосредоточиться на предсказании смертности среди пациентов с определенными заболеваниями, например, сердечно-сосудистыми. Это позволило нам сузить область исследования и получить более точные результаты. После этого мы приступили к сбору и подготовке данных.
Сбор данных оказался сложной задачей. Медицинские записи часто хранятся в разных форматах, разбросаны по разным базам данных и содержат много пропусков и ошибок. Нам пришлось приложить немало усилий, чтобы собрать все необходимые данные, очистить их и привести к единому формату. Это был трудоемкий, но крайне важный этап, поскольку качество данных напрямую влияет на качество модели машинного обучения.
Какие данные мы использовали? Вот примерный список:
- Возраст и пол пациента
- История болезней (диагнозы, перенесенные операции)
- Результаты анализов (кровь, моча, ЭКГ и т.д.)
- Принимаемые лекарства
- Образ жизни (курение, употребление алкоголя, физическая активность)
- Социально-экономический статус
Мы также столкнулись с проблемой конфиденциальности данных. Медицинская информация является очень чувствительной, и мы должны были обеспечить ее защиту в соответствии с законом. Мы использовали различные методы анонимизации и шифрования, чтобы предотвратить утечку данных.
Выбор модели машинного обучения
После подготовки данных мы приступили к выбору модели машинного обучения. Мы рассматривали разные варианты, включая логистическую регрессию, деревья решений, случайный лес, градиентный бустинг и нейронные сети. Каждый из этих методов имеет свои преимущества и недостатки, и выбор зависит от конкретной задачи и данных.
Мы решили начать с более простых моделей, таких как логистическая регрессия и деревья решений, чтобы получить базовое представление о данных и выявить наиболее важные факторы, влияющие на смертность. Затем мы перешли к более сложным моделям, таким как случайный лес и градиентный бустинг, которые обычно дают более точные результаты.
Нейронные сети также казались перспективным вариантом, но они требуют большого количества данных и тщательной настройки. Мы решили отложить их использование на более поздний этап, когда у нас будет больше опыта и ресурсов.
Оценка производительности модели
После обучения модели необходимо оценить ее производительность. Мы использовали различные метрики, такие как точность, полнота, F1-мера и AUC-ROC. Точность показывает, какую долю пациентов модель правильно классифицировала как умерших или выживших. Полнота показывает, какую долю умерших пациентов модель правильно идентифицировала. F1-мера является гармоническим средним между точностью и полнотой. AUC-ROC показывает, насколько хорошо модель различает пациентов с высоким и низким риском смертности.
Мы также использовали кросс-валидацию, чтобы убедиться, что модель не переобучается на обучающих данных и хорошо обобщается на новые данные. Кросс-валидация заключается в разделении данных на несколько частей и обучении модели на одних частях, а затем тестировании на других. Этот процесс повторяется несколько раз, и результаты усредняются.
Мы обнаружили, что случайный лес и градиентный бустинг дают наилучшие результаты на наших данных. Они смогли предсказать смертность с точностью около 80-85%, что является очень хорошим показателем.
Интерпретация результатов и внедрение в практику
После оценки производительности модели необходимо интерпретировать результаты и внедрить их в практику. Мы хотели понять, какие факторы оказывают наибольшее влияние на смертность, и как мы можем использовать эту информацию для улучшения лечения пациентов.
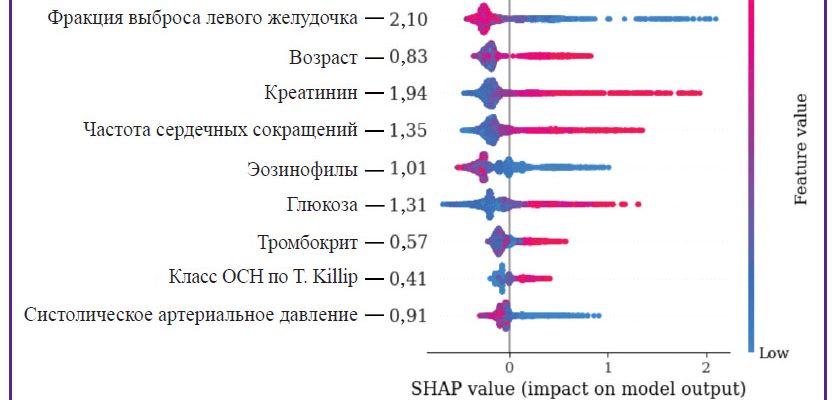
Мы обнаружили, что возраст, история болезней, результаты анализов и принимаемые лекарства являются наиболее важными факторами, влияющими на смертность. Это неудивительно, но машинное обучение позволило нам точно оценить вклад каждого фактора и выявить некоторые неочевидные закономерности.
Например, мы обнаружили, что определенные комбинации лекарств могут повышать риск смертности, даже если каждое лекарство в отдельности является безопасным. Это знание может помочь врачам более внимательно выбирать лекарства для своих пациентов.
«Будущее принадлежит тем, кто верит в красоту своей мечты.» ─ Элеонора Рузвельт
Мы также разработали инструмент, который позволяет врачам вводить данные о пациенте и получать прогноз риска смертности. Этот инструмент может помочь врачам принимать более обоснованные решения о лечении и профилактике заболеваний.
Проблемы и вызовы
Наш путь к использованию машинного обучения для предсказания смертности не был легким. Мы столкнулись с рядом проблем и вызовов, которые потребовали от нас много усилий и изобретательности.
- Недостаток данных: В некоторых случаях у нас не было достаточно данных для обучения модели. Это особенно актуально для редких заболеваний или специфических групп пациентов.
- Несбалансированные данные: В большинстве случаев количество выживших пациентов намного превышало количество умерших. Это может привести к тому, что модель будет предсказывать выживание почти для всех пациентов, даже если у них высокий риск смертности.
- Пропуски в данных: Медицинские записи часто содержат много пропусков. Нам пришлось разработать методы заполнения пропусков, чтобы не потерять важную информацию.
- Предвзятость данных: Данные могут содержать предвзятости, которые отражают неравенство в доступе к медицинской помощи или дискриминацию определенных групп пациентов. Нам пришлось учитывать эти предвзятости при обучении модели.
- Интерпретируемость модели: Некоторые модели машинного обучения, такие как нейронные сети, сложно интерпретировать. Это может затруднить понимание того, почему модель принимает определенные решения.
- Внедрение в практику: Внедрение модели машинного обучения в практику требует изменения рабочих процессов и обучения персонала. Это может быть сложно и потребовать много времени и ресурсов.
Мы старались решать эти проблемы, используя различные методы и подходы. Мы собирали дополнительные данные, использовали методы балансировки данных, разрабатывали алгоритмы заполнения пропусков, учитывали предвзятости при обучении модели и старались выбирать модели, которые легко интерпретировать. Мы также активно сотрудничали с врачами и медсестрами, чтобы убедиться, что наша модель соответствует их потребностям и может быть успешно внедрена в практику.
Уроки и выводы
Наш опыт использования машинного обучения для предсказания смертности был очень ценным. Мы узнали много нового о данных, моделях машинного обучения и проблемах здравоохранения. Мы также сделали несколько важных выводов, которыми хотим поделиться:
- Машинное обучение может быть мощным инструментом для улучшения здравоохранения.
- Качество данных имеет решающее значение для успеха модели машинного обучения.
- Необходимо тщательно выбирать модель машинного обучения и оценивать ее производительность.
- Необходимо интерпретировать результаты модели и внедрять их в практику.
- Необходимо учитывать проблемы и вызовы, связанные с использованием машинного обучения в здравоохранении.
Мы надеемся, что наш опыт будет полезен другим исследователям и специалистам, которые работают в области машинного обучения и здравоохранения. Мы верим, что машинное обучение может сыграть важную роль в улучшении здоровья людей и снижении смертности.
Что дальше?
Мы не собираемся останавливаться на достигнутом. Мы планируем продолжать исследования в области машинного обучения и здравоохранения, разрабатывать новые модели и инструменты, и внедрять их в практику. Мы также хотим поделиться нашими знаниями и опытом с другими, чтобы помочь им использовать машинное обучение для улучшения здоровья людей.
Мы планируем расширить область применения наших моделей, включив в них другие заболевания и группы пациентов. Мы также хотим использовать более сложные модели, такие как нейронные сети, чтобы получить более точные результаты. Мы будем продолжать собирать данные и улучшать их качество. Мы будем активно сотрудничать с врачами и медсестрами, чтобы убедиться, что наши модели соответствуют их потребностям и могут быть успешно внедрены в практику.
Мы уверены, что будущее здравоохранения связано с машинным обучением. Мы будем продолжать работать над тем, чтобы сделать это будущее реальностью.
Подробнее
| Алгоритмы предсказания смертности | Анализ медицинских данных МО | Машинное обучение в здравоохранении | Прогнозирование выживаемости пациентов | Оценка риска смертности |
|---|---|---|---|---|
| Модели для предсказания смертности | Классификация пациентов по риску | Применение МО в кардиологии | Прогнозирование исходов лечения | Инструменты для анализа смертности |